19 Solutions to exercises
19.1 Chapter 3
For annual values, see 19.1:
data_ml %>%
group_by(date) %>%
mutate(growth = Pb > median(Pb)) %>% # Creates the sort
ungroup() %>% # Ungroup
mutate(year = lubridate::year(date)) %>% # Creates a year variable
group_by(year, growth) %>% # Analyze by year & sort
summarize(ret = mean(R1M_Usd)) %>% # Compute average return
ggplot(aes(x = year, y = ret, fill = growth)) + geom_col(position = "dodge") + # Plot!
theme(legend.position = c(0.7, 0.8)) + theme_bw()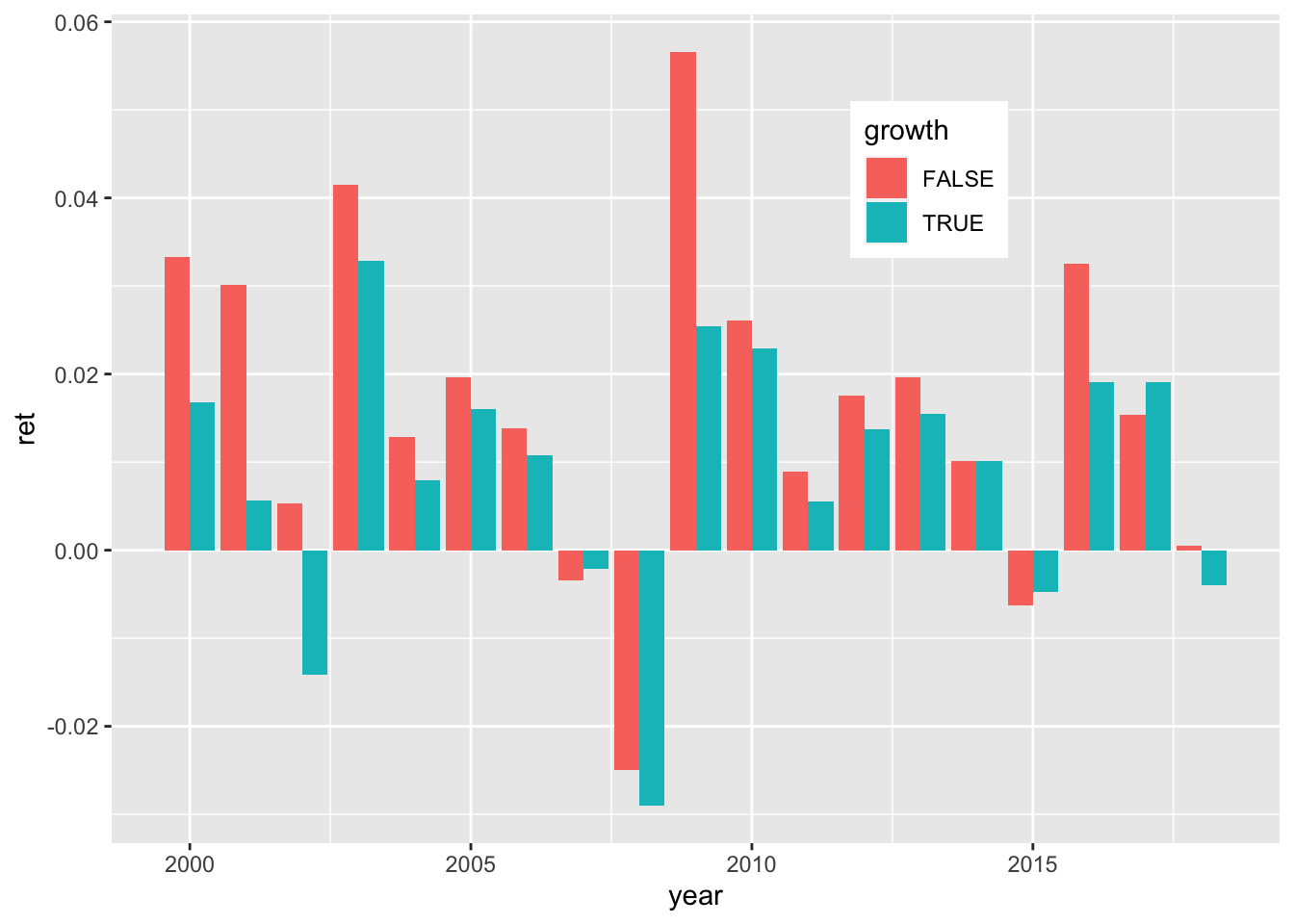
FIGURE 19.1: The value factor: annual returns.
For monthly values, see 19.2:
returns_m <- data_ml %>%
group_by(date) %>%
mutate(growth = Pb > median(Pb)) %>% # Creates the sort
group_by(date, growth) %>% # Analyze by date & sort
summarize(ret = mean(R1M_Usd)) %>% # Compute average return
spread(key = growth, value = ret) %>% # Pivot to wide matrix format
ungroup()
colnames(returns_m)[2:3] <- c("value", "growth") # Changing column names
returns_m %>%
mutate(value = cumprod(1 + value), # From returns to portf. values
growth = cumprod(1 + growth)) %>%
gather(key = portfolio, value = value, -date) %>% # Back in tidy format
ggplot(aes(x = date, y = value, color = portfolio)) + geom_line() + # Plot!
theme(legend.position = c(0.7, 0.8)) + theme_bw()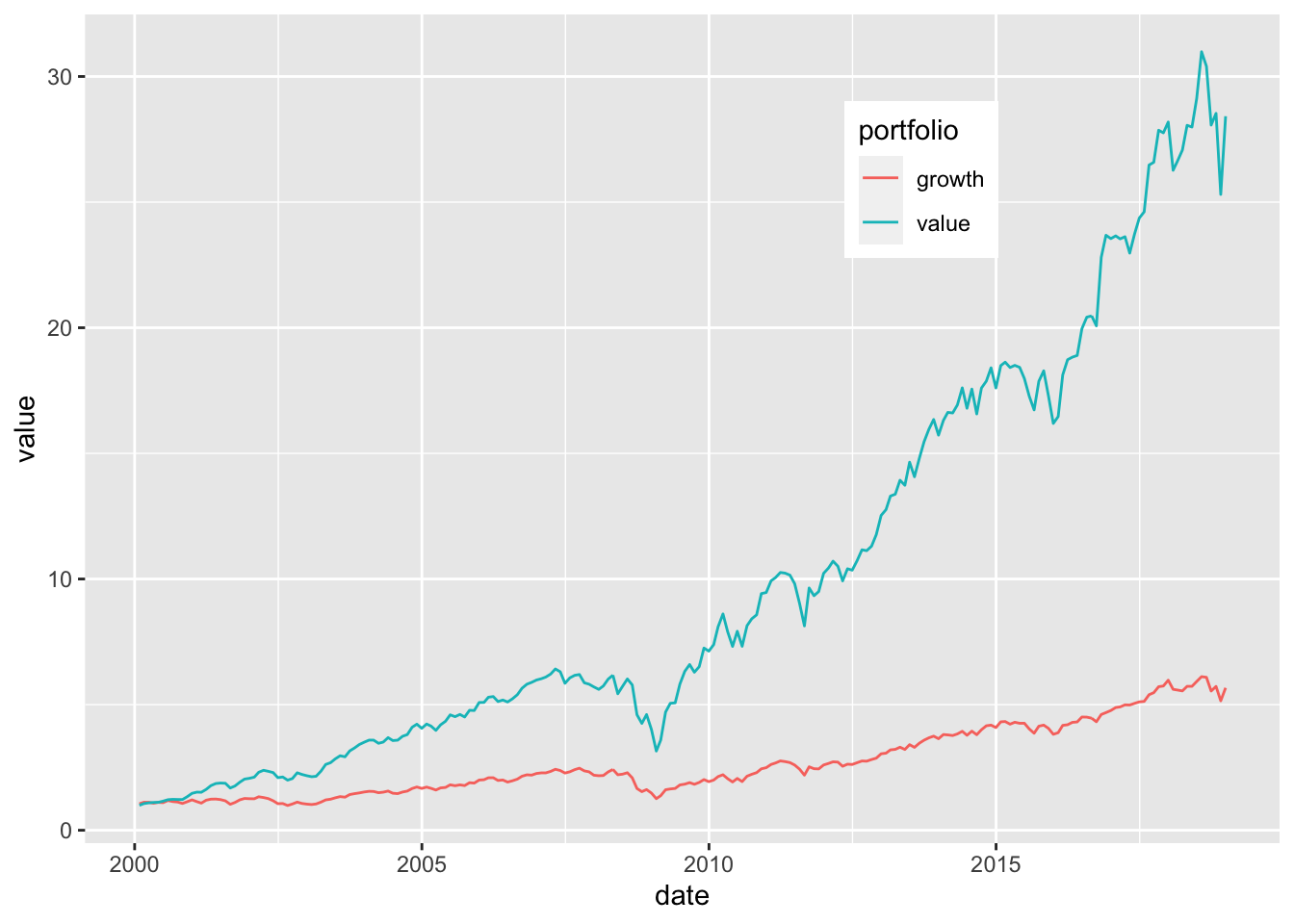
FIGURE 19.2: The value factor: portfolio values.
Portfolios based on quartiles, using the tidyverse only. We rely heavily on the fact that features are uniformized, i.e., that their distribution is uniform for each given date. Overall, small firms outperform heavily (see Figure 19.3).
data_ml %>%
mutate(small = Mkt_Cap_6M_Usd <= 0.25, # Small firms...
medium = Mkt_Cap_6M_Usd > 0.25 & Mkt_Cap_6M_Usd <= 0.5,
large = Mkt_Cap_6M_Usd > 0.5 & Mkt_Cap_6M_Usd <= 0.75,
xl = Mkt_Cap_6M_Usd > 0.75, # ...Xlarge firms
year = year(date)) %>%
group_by(year) %>%
summarize(small = mean(small * R1M_Usd), # Compute avg returns
medium = mean(medium * R1M_Usd),
large = mean(large * R1M_Usd),
xl = mean(xl * R1M_Usd)) %>%
gather(key = size, value = return, -year) %>%
ggplot(aes(x = year, y = return, fill = size)) +
geom_col(position = "dodge") + theme_bw()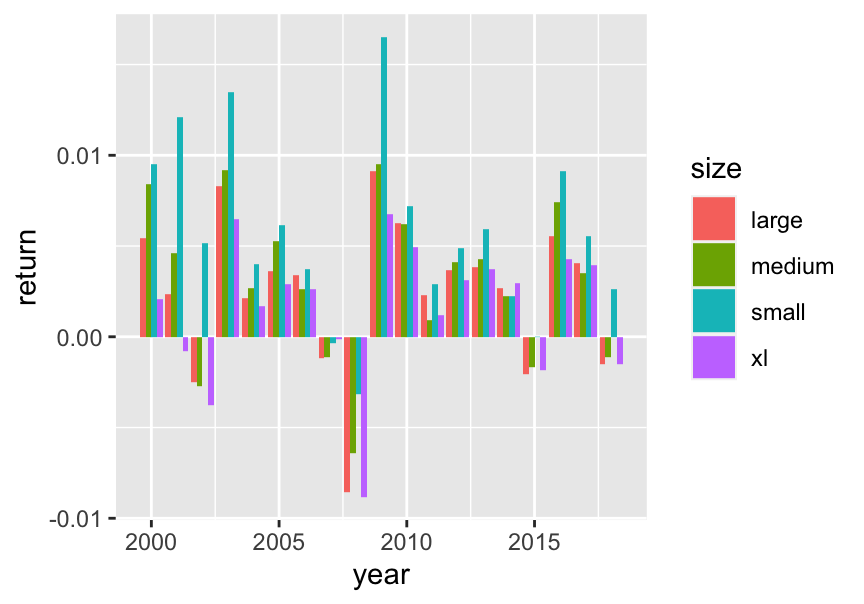
FIGURE 19.3: The value factor: portfolio values.
19.2 Chapter 4
Below, we import a credit spread supplied by Bank of America. Its symbol/ticker is “BAMLC0A0CM”. We apply the data expansion on the small number of predictors to save memory space. One important trick that should not be overlooked is the uniformization step after the product (4.3) is computed. Indeed, we want the new features to have the same properties as the old ones. If we skip this step, distributions will be altered, as we show in one example below.
We start with the data extraction and joining. It’s important to join early so as to keep the highest data frequency (daily) in order to replace missing points with close values. Joining with monthly data before replacing creates unnecessary lags.
getSymbols.FRED("BAMLC0A0CM", # Extract data
env = ".GlobalEnv",
return.class = "xts")## [1] "BAMLC0A0CM"
cred_spread <- fortify(BAMLC0A0CM) # Transform to dataframe
colnames(cred_spread) <- c("date", "spread") # Change column name
cred_spread <- cred_spread %>% # Take extraction and...
full_join(data_ml %>% dplyr::select(date), by = "date") %>% # Join!
mutate(spread = na.locf(spread)) # Replace NA by previous
cred_spread <- cred_spread[!duplicated(cred_spread),] # Remove duplicatesThe creation of the augmented dataset requires some manipulation. Features are no longer uniform as is shown in Figure 19.4.
data_cond <- data_ml %>% # Create new dataset
dplyr::select(c("stock_id", "date", features_short))
names_cred_spread <- paste0(features_short, "_cred_spread") # New column names
feat_cred_spread <- data_cond %>% # Old values
dplyr::select(features_short)
cred_spread <- data_ml %>% # Create vector of spreads
dplyr::select(date) %>%
left_join(cred_spread, by = "date")
feat_cred_spread <- feat_cred_spread * # This product creates...
matrix(cred_spread$spread, # the new values...
length(cred_spread$spread), # using duplicated...
length(features_short)) # columns
colnames(feat_cred_spread) <- names_cred_spread # New column names
data_cond <- bind_cols(data_cond, feat_cred_spread) # Aggregate old & new
data_cond %>% ggplot(aes(x = Eps_cred_spread)) + geom_histogram() # Plot example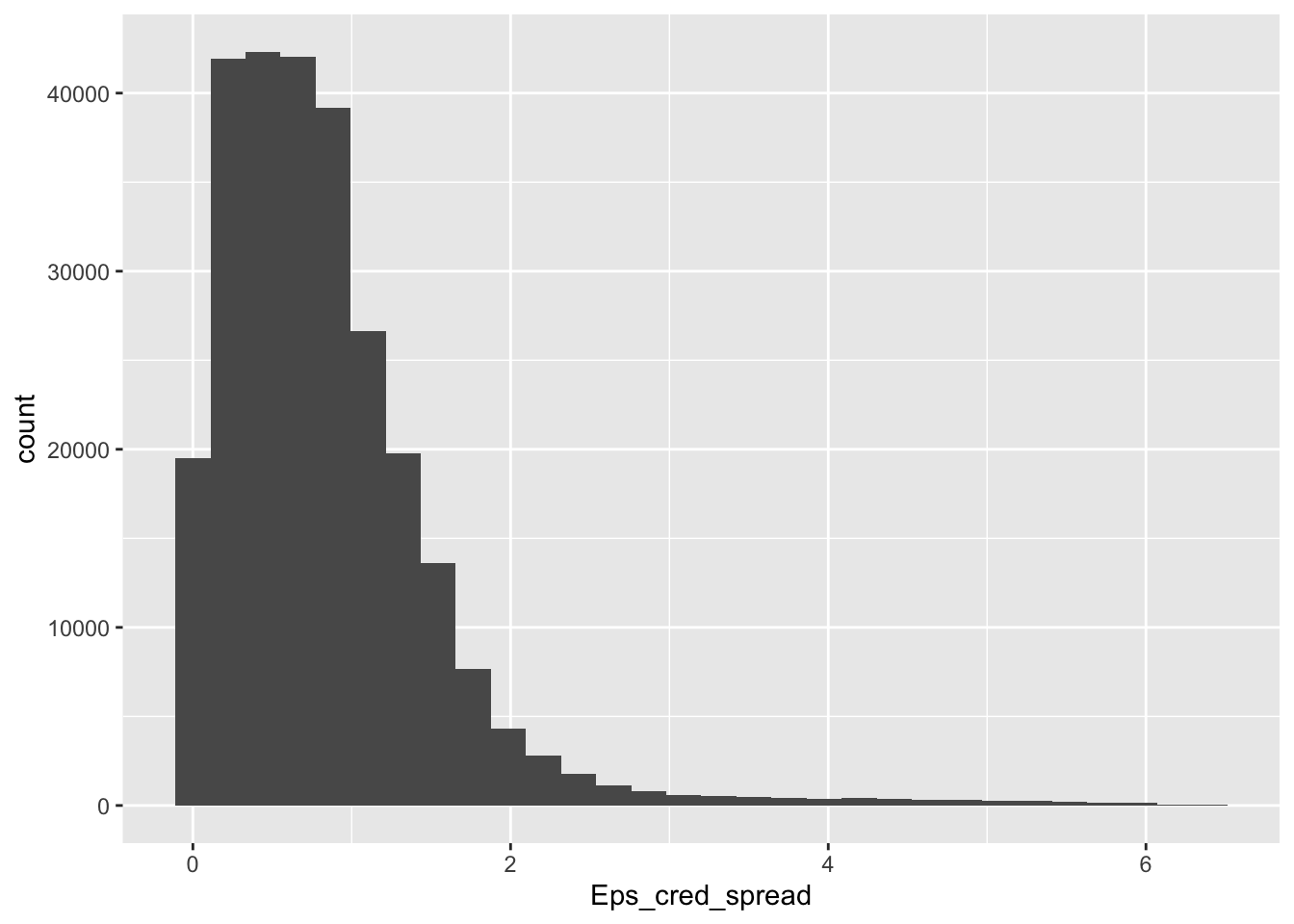
FIGURE 19.4: Distribution of Eps after conditioning.
To prevent this issue, uniformization is required and is verified in Figure 19.5.
data_cond <- data_cond %>% # From new dataset
group_by(date) %>% # Group by date and...
mutate_at(names_cred_spread, norm_unif) # Uniformize the new features
data_cond %>% ggplot(aes(x = Eps_cred_spread)) + geom_histogram(bins = 100) # Verification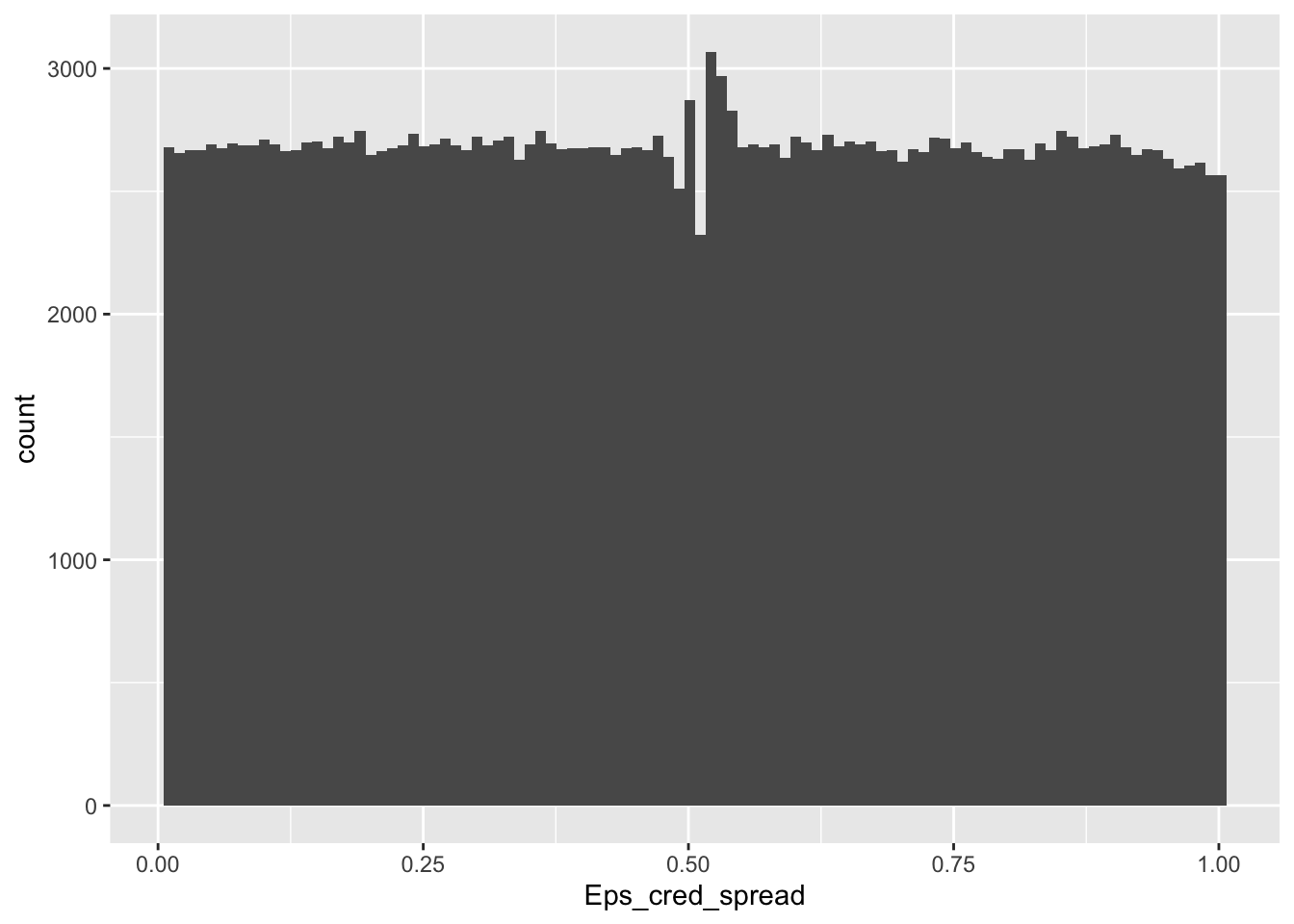
FIGURE 19.5: Distribution of uniformized conditioned feature values.
The second question naturally requires the downloading of VIX series first and the joining with the original data.
getSymbols.FRED("VIXCLS", # Extract data
env = ".GlobalEnv",
return.class = "xts")## [1] "VIXCLS"
vix <- fortify(VIXCLS) # Transform to dataframe
colnames(vix) <- c("date", "vix") # Change column name
vix <- vix %>% # Take extraction and...
full_join(data_ml %>% dplyr::select(date), by = "date") %>% # Join!
mutate(vix = na.locf(vix)) # Replace NA by previous
vix <- vix[!duplicated(vix),] # Remove duplicates
vix <- data_ml %>% # Keep original data format
dplyr::select(date) %>% # ...
left_join(vix, by = "date") # Via left_join()We can then proceed with the categorization. We create the vector label in a new (smaller) dataset but not attached to the large data_ml variable. Also, we check the balance of labels and its evolution through time (see Figure 19.6).
delta <- 0.5 # Magnitude of vix correction
vix_bar <- median(vix$vix) # Median of vix
data_vix <- data_ml %>% # Smaller dataset
dplyr::select(stock_id, date, R1M_Usd) %>%
mutate(r_minus = (-0.02) * exp(-delta*(vix$vix-vix_bar)), # r_-
r_plus = 0.02 * exp(delta*(vix$vix-vix_bar))) # r_+
data_vix <- data_vix %>%
mutate(R1M_Usd_Cvix = if_else(R1M_Usd < r_minus, -1, # New label!
if_else(R1M_Usd > r_plus, 1,0)),
R1M_Usd_Cvix = as.factor(R1M_Usd_Cvix))
data_vix %>%
mutate(year = year(date)) %>%
group_by(year, R1M_Usd_Cvix) %>%
summarize(nb = n()) %>%
ggplot(aes(x = year, y = nb, fill = R1M_Usd_Cvix)) +
geom_col() + theme_bw()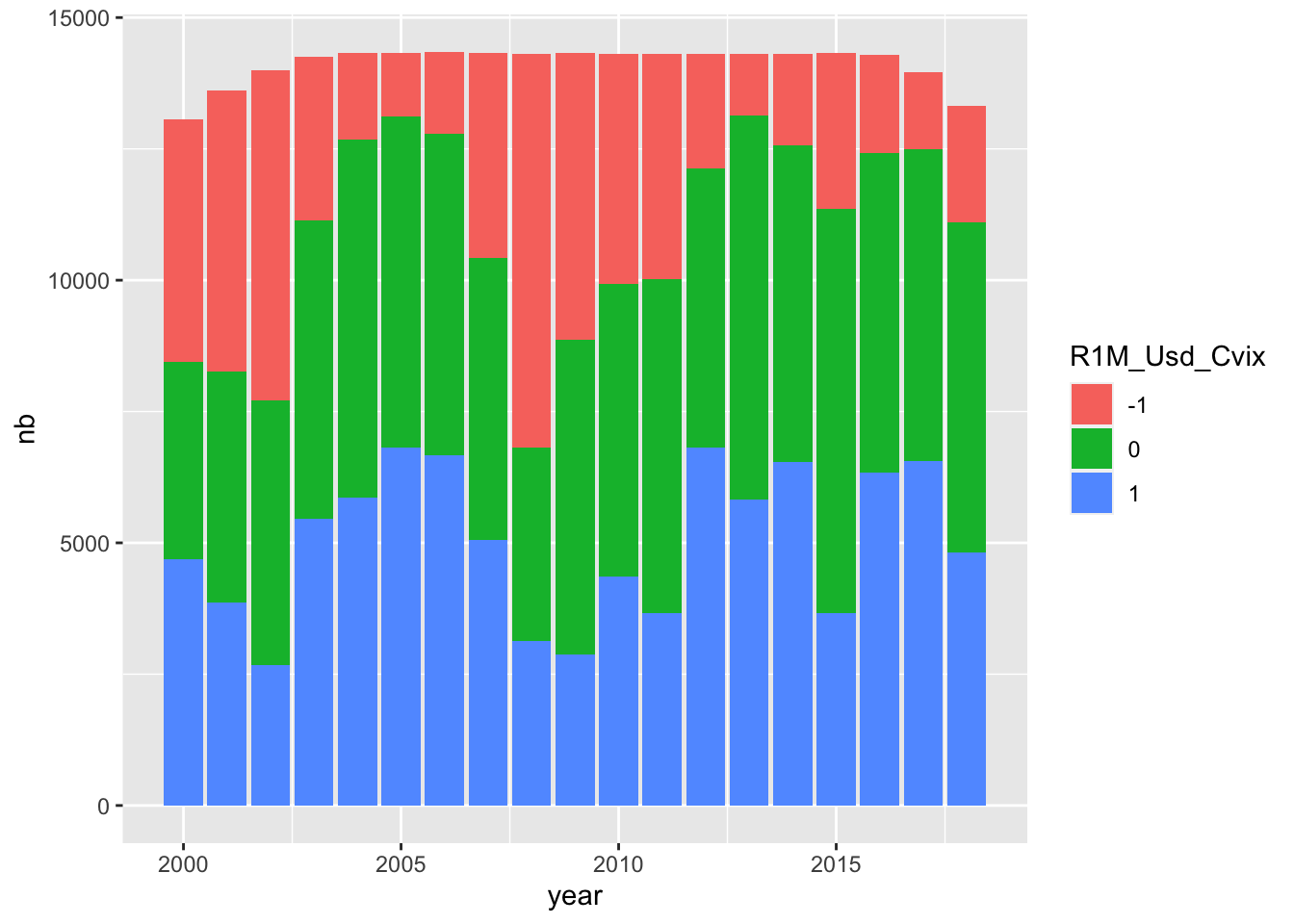
FIGURE 19.6: Evolution of categories through time.
Finally, we switch to the outliers (Figure 19.7).
data_ml %>%
ggplot(aes(x = R12M_Usd)) + geom_histogram() + theme_bw()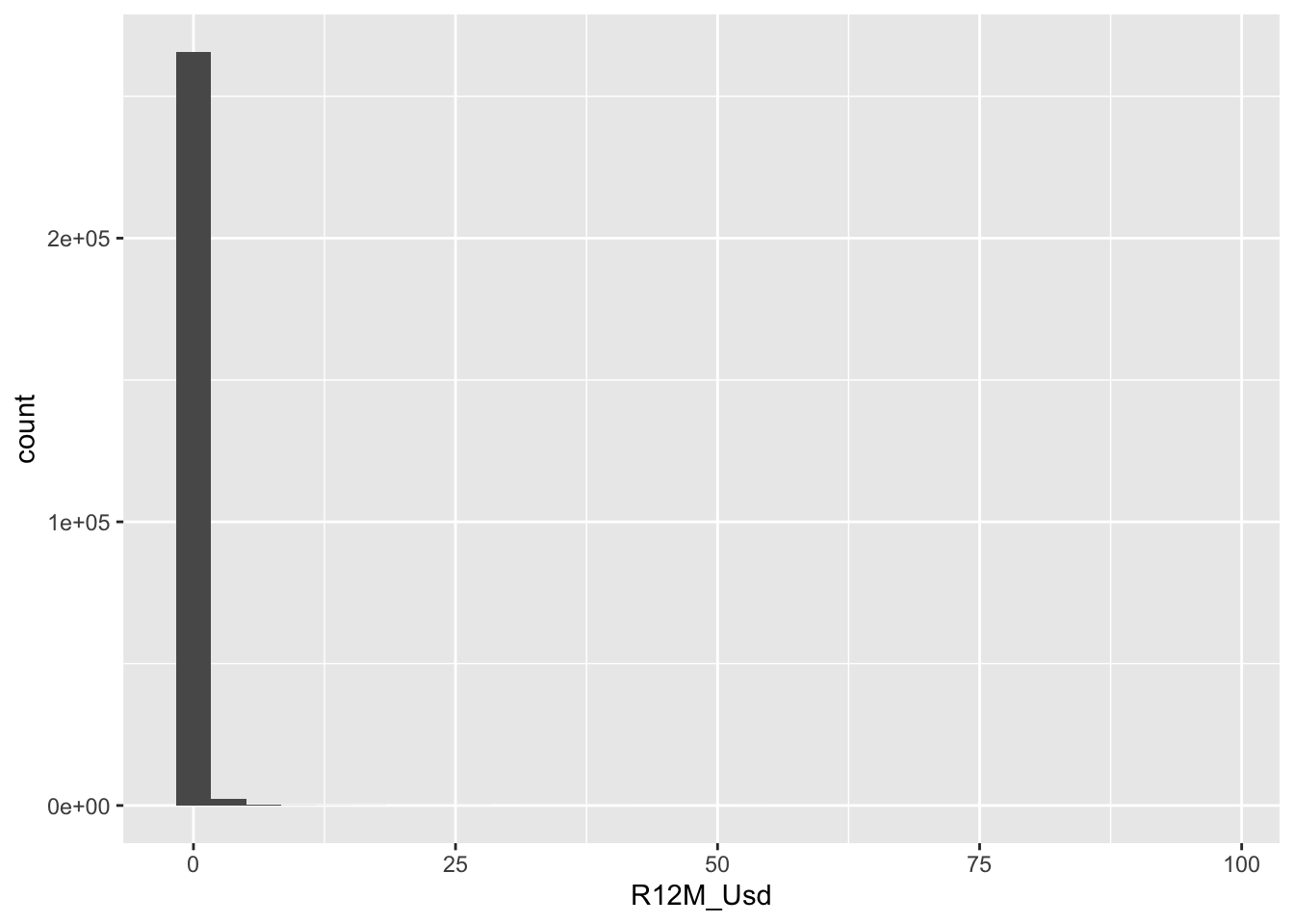
FIGURE 19.7: Outliers in the dependent variable.
Returns above 50 should indeed be rare.
## # A tibble: 8 × 3
## stock_id date R12M_Usd
## <int> <date> <dbl>
## 1 212 2000-12-31 53.0
## 2 221 2008-12-31 53.5
## 3 221 2009-01-31 55.2
## 4 221 2009-02-28 54.8
## 5 296 2002-06-30 72.2
## 6 683 2009-02-28 96.0
## 7 683 2009-03-31 64.8
## 8 862 2009-02-28 58.0The largest return comes from stock #683. Let’s have a look at the stream of monthly returns in 2009.
## # A tibble: 12 × 2
## date R1M_Usd
## <date> <dbl>
## 1 2009-01-31 -0.625
## 2 2009-02-28 0.472
## 3 2009-03-31 1.44
## 4 2009-04-30 0.139
## 5 2009-05-31 0.086
## 6 2009-06-30 0.185
## 7 2009-07-31 0.363
## 8 2009-08-31 0.103
## 9 2009-09-30 9.91
## 10 2009-10-31 0.101
## 11 2009-11-30 0.202
## 12 2009-12-31 -0.251The returns are all very high. The annual value is plausible. In addition, a quick glance at the Vol1Y values shows that the stock is the most volatile of the dataset.
19.3 Chapter 5
We recycle the training and testing data variables created in the chapter (coding section notably). In addition, we create a dedicated function and resort to the map2() function from the purrr package.
alpha_seq <- (0:10)/10 # Sequence of alpha values
lambda_seq <- 0.1^(0:5) # Sequence of lambda values
pars <- expand.grid(alpha_seq, lambda_seq) # Exploring all combinations!
alpha_seq <- pars[,1]
lambda_seq <- pars[,2]
lasso_sens <- function(alpha, lambda, x_train, y_train, x_test, y_test){ # Function
fit_temp <- glmnet(x_train, y_train, # Model
alpha = alpha, lambda = lambda)
return(sqrt(mean((predict(fit_temp, x_test) - y_test)^2))) # Output
}
rmse_elas <- map2(alpha_seq, lambda_seq, lasso_sens, # Automation
x_train = x_penalized_train, y_train = y_penalized_train,
x_test = x_penalized_test, y_test = testing_sample$R1M_Usd)
bind_cols(alpha = alpha_seq, lambda = as.factor(lambda_seq), rmse = unlist(rmse_elas)) %>%
ggplot(aes(x = alpha, y = rmse, fill = lambda)) + geom_col() + facet_grid(lambda ~.) +
coord_cartesian(ylim = c(0.19,0.193)) + theme_bw()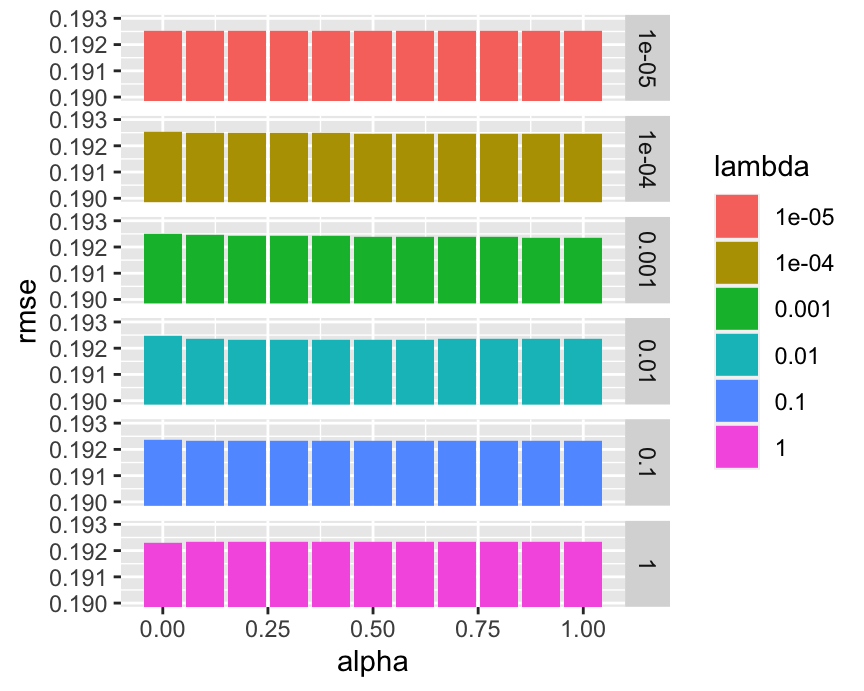
FIGURE 19.8: Performance of elasticnet across parameter values.
As is outlined in Figure 19.8, the parameters have a very marginal impact. Maybe the model is not a good fit for the task.
19.4 Chapter 6
fit1 <- rpart(formula,
data = training_sample, # Data source: full sample
cp = 0.001) # Precision: smaller = more leaves
mean((predict(fit1, testing_sample) - testing_sample$R1M_Usd)^2) ## [1] 0.04018973
fit2 <- rpart(formula,
data = training_sample, # Data source: full sample
cp = 0.01) # Precision: smaller = more leaves
mean((predict(fit2, testing_sample) - testing_sample$R1M_Usd)^2) # Test!## [1] 0.03699696
rpart.plot(fit1) # Plot the first tree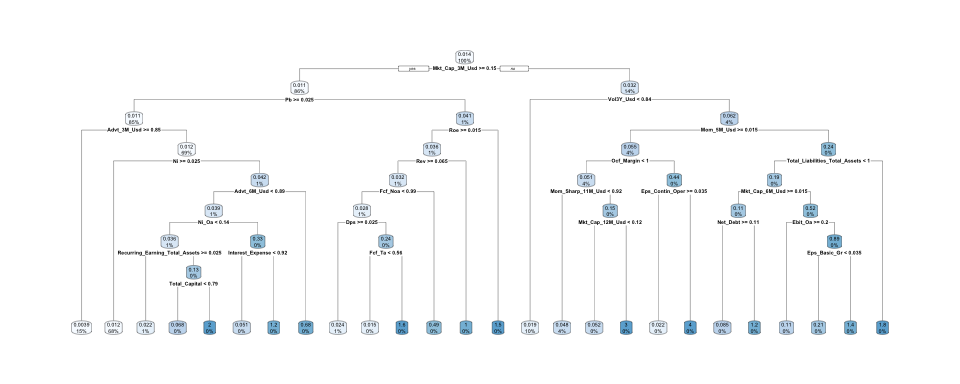
FIGURE 19.9: Sample (complex) tree.
The first model (Figure 19.9) is too precise: going into the details of the training sample does not translate to good performance out-of-sample. The second, simpler model, yields better results.
n_trees <- c(10, 20, 40, 80, 160)
mse_RF <- 0
for(j in 1:length(n_trees)){ # No need for functional programming here...
fit_temp <- randomForest(
as.formula(paste("R1M_Usd ~", paste(features_short, collapse = " + "))), # New formula!
data = training_sample, # Data source: training sample
sampsize = 30000, # Size of (random) sample for each tree
replace = TRUE, # Is the sampling done with replacement?
ntree = n_trees[j], # Nb of random trees
mtry = 5) # Nb of predictors for each tree
mse_RF[j] <- mean((predict(fit_temp, testing_sample) - testing_sample$R1M_Usd)^2)
}
mse_RF## [1] 0.03967754 0.03885924 0.03766900 0.03696370 0.03699772Trees are by definition random so results can vary from test to test. Overall, large numbers of trees are preferable and the reason is that each new tree tells a new story and diversifies the risk of the whole forest. Some more technical details of why that may be the case are outlined in the original paper by Breiman (2001).
For the last exercises, we recycle the formula used in Chapter 6.
tree_2008 <- rpart(formula,
data = data_ml %>% filter(year(date) == 2008), # Data source: 2008
cp = 0.001,
maxdepth = 2)
rpart.plot(tree_2008)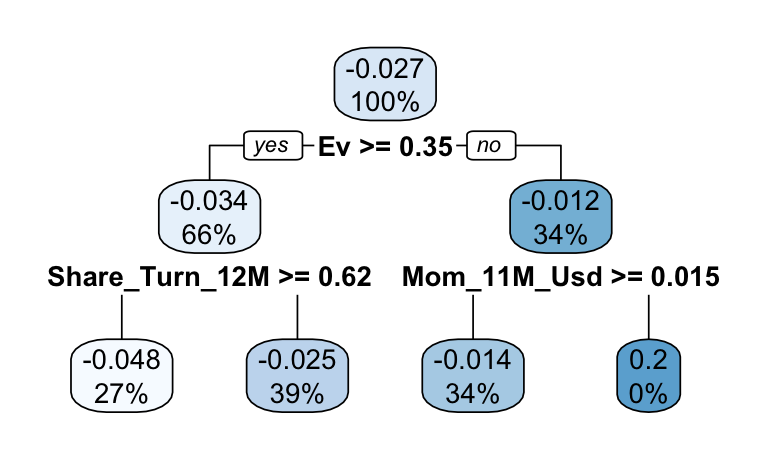
FIGURE 19.10: Tree for 2008.
The first splitting criterion in Figure 19.10 is enterprise value (EV). EV is an indicator that adjusts market capitalization by substracting debt and adding cash. It is a more faithful account of the true value of a company. In 2008, the companies that fared the least poorly were those with the highest EV (i.e., large, robust firms).
tree_2009 <- rpart(formula,
data = data_ml %>% filter(year(date) == 2009), # Data source: 2009
cp = 0.001,
maxdepth = 2)
rpart.plot(tree_2009)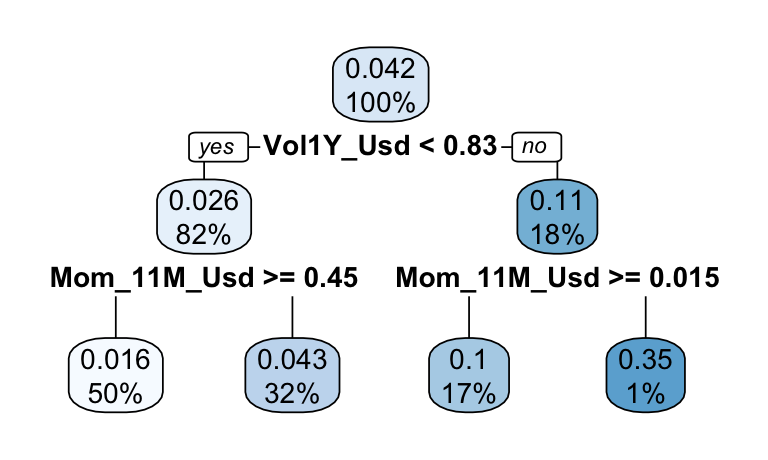
FIGURE 19.11: Tree for 2009.
In 2009 (Figure 19.11), the firms that recovered the fastest were those that experienced high volatility in the past (likely, downwards volatility). Momentum is also very important: the firms with the lowest past returns are those that rebound the fastest. This is a typical example of the momentum crash phenomenon studied in Barroso and Santa-Clara (2015) and K. Daniel and Moskowitz (2016). The rationale is the following: after a market downturn, the stocks with the most potential for growth are those that have suffered the largest losses. Consequently, the negative (short) leg of the momentum factor performs very well, often better than the long leg. And indeed, being long in the momentum factor in 2009 would have generated negative profits.
19.5 Chapter 7: the autoencoder model & universal approximation
First, it is imperative to format the inputs properly. To avoid any issues, we work with perfectly rectangular data and hence restrict the investment set to the stocks with no missing points. Dimensions must also be in the correct order.
data_short <- data_ml %>% # Shorter dataset
filter(stock_id %in% stock_ids_short) %>%
dplyr::select(c("stock_id", "date",features_short, "R1M_Usd"))
dates <- unique(data_short$date) # Vector of dates
N <- length(stock_ids_short) # Dimension for assets
Tt <- length(dates) # Dimension for dates
K <- length(features_short) # Dimension for features
factor_data <- data_short %>% # Factor side date
dplyr::select(date, stock_id, R1M_Usd) %>%
spread(key = stock_id, value = R1M_Usd) %>%
dplyr::select(-date) %>%
as.matrix()
beta_data <- array(unlist(data_short %>% # Beta side data: beware the permutation below!
dplyr::select(-stock_id, -date, -R1M_Usd)),
dim = c(N, Tt, K))
beta_data <- aperm(beta_data, c(2,1,3)) # PermutationNext, we turn to the specification of the network, using a functional API form.
main_input <- layer_input(shape = c(N), name = "main_input") # Main input: returns
factor_network <- main_input %>% # Def of factor side network
layer_dense(units = 8, activation = "relu", name = "layer_1_r") %>%
layer_dense(units = 4, activation = "tanh", name = "layer_2_r")
aux_input <- layer_input(shape = c(N,K), name = "aux_input") # Aux input: characteristics
beta_network <- aux_input %>% # Def of beta side network
layer_dense(units = 8, activation = "relu", name = "layer_1_l") %>%
layer_dense(units = 4, activation = "tanh", name = "layer_2_l") %>%
layer_permute(dims = c(2,1), name = "layer_3_l") # Permutation!
main_output <- layer_dot(c(beta_network, factor_network), # Product of 2 networks
axes = 1, name = "main_output")
model_ae <- keras_model( # AE Model specs
inputs = c(main_input, aux_input),
outputs = c(main_output)
)Finally, we ask for the structure of the model, and train it.
summary(model_ae) # See model details / architecture## Model: "model_1"
## __________________________________________________________________________________________
## Layer (type) Output Shape Param # Connected to
## ==========================================================================================
## aux_input (InputLayer) [(None, 793, 7)] 0
## __________________________________________________________________________________________
## layer_1_l (Dense) (None, 793, 8) 64 aux_input[0][0]
## __________________________________________________________________________________________
## main_input (InputLayer) [(None, 793)] 0
## __________________________________________________________________________________________
## layer_2_l (Dense) (None, 793, 4) 36 layer_1_l[0][0]
## __________________________________________________________________________________________
## layer_1_r (Dense) (None, 8) 6352 main_input[0][0]
## __________________________________________________________________________________________
## layer_3_l (Permute) (None, 4, 793) 0 layer_2_l[0][0]
## __________________________________________________________________________________________
## layer_2_r (Dense) (None, 4) 36 layer_1_r[0][0]
## __________________________________________________________________________________________
## main_output (Dot) (None, 793) 0 layer_3_l[0][0]
## layer_2_r[0][0]
## ==========================================================================================
## Total params: 6,488
## Trainable params: 6,488
## Non-trainable params: 0
## __________________________________________________________________________________________
model_ae %>% keras::compile( # Learning parameters
optimizer = "rmsprop",
loss = "mean_squared_error"
)
model_ae %>% fit( # Learning function
x = list(main_input = factor_data, aux_input = beta_data),
y = list(main_output = factor_data),
epochs = 20, # Nb rounds
batch_size = 49 # Nb obs. per round
)For the second exercise, we use a simple architecture. The activation function, number of epochs and batch size may matter…
model_ua <- keras_model_sequential()
model_ua %>% # This defines the structure of the network, i.e. how layers are organized
layer_dense(units = 16, activation = 'sigmoid', input_shape = 1) %>%
layer_dense(units = 1) #
model_ua %>% keras::compile( # Model specification
loss = 'mean_squared_error', # Loss function
optimizer = optimizer_rmsprop(), # Optimisation method (weight updating)
metrics = c('mean_absolute_error') # Output metric
)
summary(model_ua) # A simple model!## Model: "sequential_7"
## __________________________________________________________________________________________
## Layer (type) Output Shape Param #
## ==========================================================================================
## dense_22 (Dense) (None, 16) 32
## __________________________________________________________________________________________
## dense_21 (Dense) (None, 1) 17
## ==========================================================================================
## Total params: 49
## Trainable params: 49
## Non-trainable params: 0
## __________________________________________________________________________________________
fit_ua <- model_ua %>%
fit(seq(0, 6, by = 0.001) %>% matrix(ncol = 1), # Training data = x
sin(seq(0, 6, by = 0.001)) %>% matrix(ncol = 1), # Training label = y
epochs = 30, batch_size = 64 # Training parameters
) In full disclosure, to improve the fit, we also increase the sample size. We show the improvement in the figure below.
library(patchwork)
model_ua2 <- keras_model_sequential()
model_ua2 %>% # This defines the structure of the network, i.e. how layers are organized
layer_dense(units = 128, activation = 'sigmoid', input_shape = 1) %>%
layer_dense(units = 1) #
model_ua2 %>% keras::compile( # Model specification
loss = 'mean_squared_error', # Loss function
optimizer = optimizer_rmsprop(), # Optimisation method (weight updating)
metrics = c('mean_absolute_error') # Output metric
)
summary(model_ua2) # A simple model!## Model: "sequential_8"
## __________________________________________________________________________________________
## Layer (type) Output Shape Param #
## ==========================================================================================
## dense_24 (Dense) (None, 128) 256
## __________________________________________________________________________________________
## dense_23 (Dense) (None, 1) 129
## ==========================================================================================
## Total params: 385
## Trainable params: 385
## Non-trainable params: 0
## __________________________________________________________________________________________
fit_ua2 <- model_ua2 %>%
fit(seq(0, 6, by = 0.0002) %>% matrix(ncol = 1), # Training data = x
sin(seq(0, 6, by = 0.0002)) %>% matrix(ncol = 1), # Training label = y
epochs = 60, batch_size = 64 # Training parameters
)
tibble(x = seq(0, 6, by = 0.001)) %>%
ggplot() +
geom_line(aes(x = x, y = predict(model_ua, x), color = "Small model")) +
geom_line(aes(x = x, y = predict(model_ua2, x), color = "Large model")) +
stat_function(fun = sin, aes(color = "sin(x) function")) +
scale_color_manual(values = c("#EEAA33", "#3366CC", "#000000")) + theme_bw()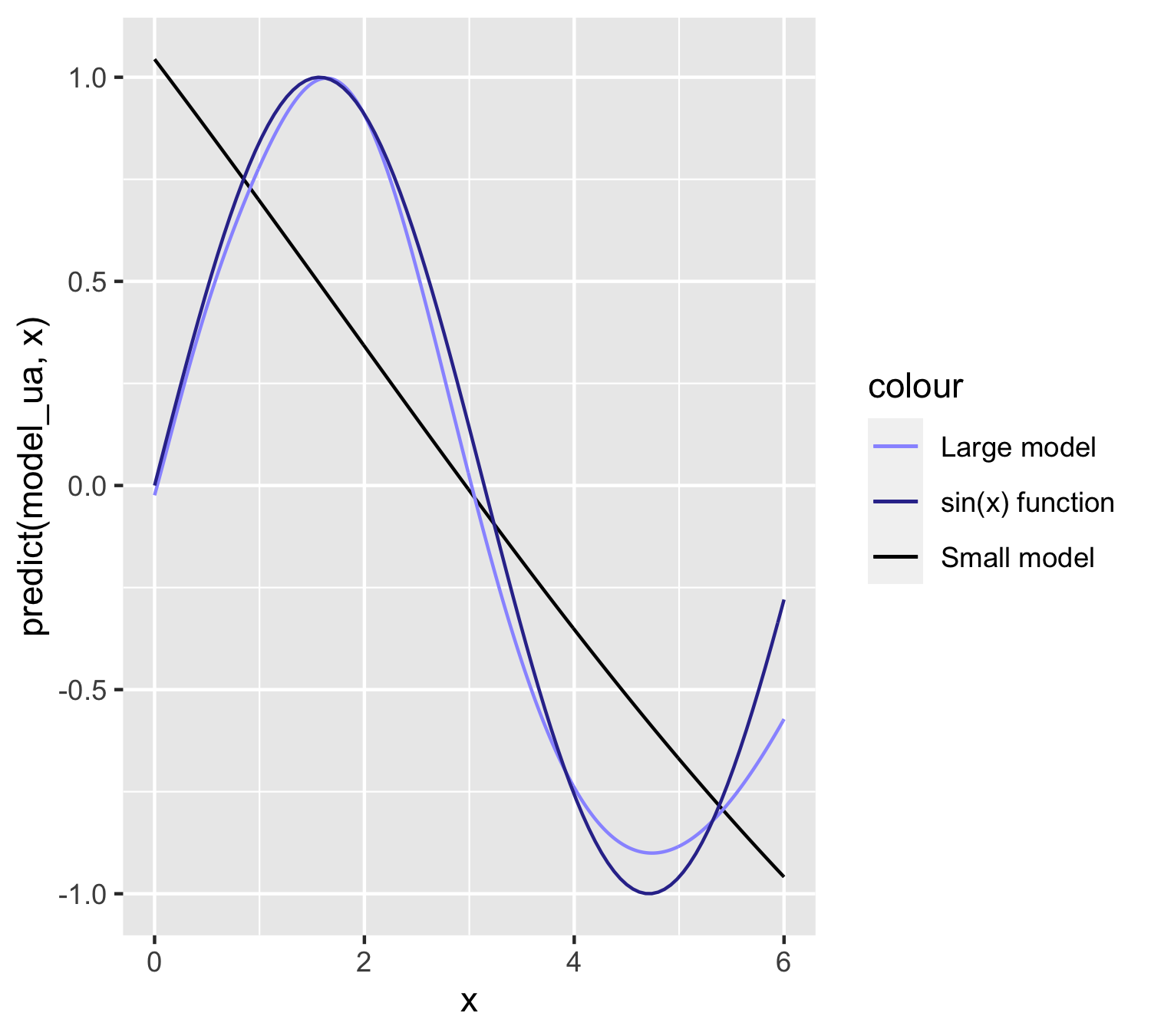
FIGURE 19.12: Case with 128 units. The sine function in light blue and approximation in black.
19.6 Chapter 8
Since we are going to reproduce a similar analysis several times, let’s simplify the task with 2 tips. First, by using default parameter values that will be passed as common arguments to the svm function. Second, by creating a custom function that computes the MSE. Third, by resorting to functional calculus via the map function from the purrr package. Below, we recycle datasets created in Chapter 6.
mse <- function(fit, features, label){ # MSE function
return(mean((predict(fit, features)-label)^2))
}
par_list <- list(y = train_label_xgb[1:10000], # From Tree chapter
x = train_features_xgb[1:10000,],
type = "eps-regression",
epsilon = 0.1, # Width of strip for errors
gamma = 0.5, # Constant in the radial kernel
cost = 0.1)
svm_par <- function(kernel, par_list){ # Function for SVM fit automation
require(e1071)
return(do.call(svm, c(kernel = kernel, par_list)))
}
kernels <- c("linear", "radial", "polynomial", "sigmoid") # Kernels
fit_svm_par <- map(kernels, svm_par, par_list = par_list) # SVM models
map(fit_svm_par, mse, # MSEs
features = test_feat_short, # From SVM chapter
label = testing_sample$R1M_Usd)## [[1]]
## [1] 0.03849786
##
## [[2]]
## [1] 0.03924576
##
## [[3]]
## [1] 0.03951328
##
## [[4]]
## [1] 334.8173The first two kernels yield the best fit, while the last one should be avoided. Note that apart from the linear kernel, all other options require parameters. We have used the default ones, which may explain the poor performance of some nonlinear kernels.
Below, we train an SVM model on a training sample with all observations but that is limited to the 7 major predictors. Even with a smaller number of features, the training is time consuming.
svm_full <- svm(y = train_label_xgb, # Train label
x = train_features_xgb, # Training features
type = "eps-regression", # SVM task type (see LIBSVM documentation)
kernel = "linear", # SVM kernel
epsilon = 0.1, # Width of strip for errors
cost = 0.1) # Slack variable penalisation
test_feat_short <- dplyr::select(testing_sample,features_short) # Test set
mean(predict(svm_full, test_feat_short) * testing_sample$R1M_Usd > 0) # Hit ratio## [1] 0.490343This figure is very low. Below, we test a very simple form of boosted trees, for comparison purposes.
xgb_full <- xgb.train(data = train_matrix_xgb, # Data source
eta = 0.3, # Learning rate
objective = "reg:linear", # Objective function
max_depth = 4, # Maximum depth of trees
nrounds = 60 # Number of trees used (bit low here)
)## [14:44:45] WARNING: amalgamation/../src/objective/regression_obj.cu:188: reg:linear is now deprecated in favor of reg:squarederror.## [1] 0.5017377The forecasts are slightly better, but the computation time is lower. Two reasons why the models perform poorly:
- there are not enough predictors;
- the models are static: they do not adjust dynamically to macro-conditions.
19.7 Chapter 11: ensemble neural network
First, we create the three feature sets. The first one gets all multiples of 3 between 3 and 93. The second one gets the same indices, minus one, and the third one, the initial indices minus two.
feat_train_1 <- training_sample %>% dplyr::select(features[3*(1:31)]) %>% # First set of feats
as.matrix()
feat_train_2 <- training_sample %>% dplyr::select(features[3*(1:31)-1]) %>% # Second set of feats
as.matrix()
feat_train_3 <- training_sample %>% dplyr::select(features[3*(1:31)-2]) %>% # Third set of feats
as.matrix()
feat_test_1 <- testing_sample %>% dplyr::select(features[3*(1:31)]) %>% # Test features 1
as.matrix()
feat_test_2 <- testing_sample %>% dplyr::select(features[3*(1:31)-1]) %>% # Test features 2
as.matrix()
feat_test_3 <- testing_sample %>% dplyr::select(features[3*(1:31)-2]) %>% # Test features 3
as.matrix() Then, we specify the network structure. First, the 3 independent networks, then the aggregation.
first_input <- layer_input(shape = c(31), name = "first_input") # First input
first_network <- first_input %>% # Def of 1st network
layer_dense(units = 8, activation = "relu", name = "layer_1") %>%
layer_dense(units = 2, activation = 'softmax') # Softmax for categ. output
second_input <- layer_input(shape = c(31), name = "second_input") # Second input
second_network <- second_input %>% # Def of 2nd network
layer_dense(units = 8, activation = "relu", name = "layer_2") %>%
layer_dense(units = 2, activation = 'softmax') # Softmax for categ. output
third_input <- layer_input(shape = c(31), name = "third_input") # Third input
third_network <- third_input %>% # Def of 3rd network
layer_dense(units = 8, activation = "relu", name = "layer_3") %>%
layer_dense(units = 2, activation = 'softmax') # Softmax for categ. output
main_output <- layer_concatenate(c(first_network,
second_network,
third_network)) %>% # Combination
layer_dense(units = 2, activation = 'softmax', name = 'main_output')
model_ens <- keras_model( # Agg. Model specs
inputs = c(first_input, second_input, third_input),
outputs = c(main_output)
)Lastly, we can train and evaluate (see Figure 19.13).
summary(model_ens) # See model details / architecture## Model: "model_2"
## __________________________________________________________________________________________
## Layer (type) Output Shape Param # Connected to
## ==========================================================================================
## first_input (InputLayer) [(None, 31)] 0
## __________________________________________________________________________________________
## second_input (InputLayer) [(None, 31)] 0
## __________________________________________________________________________________________
## third_input (InputLayer) [(None, 31)] 0
## __________________________________________________________________________________________
## layer_1 (Dense) (None, 8) 256 first_input[0][0]
## __________________________________________________________________________________________
## layer_2 (Dense) (None, 8) 256 second_input[0][0]
## __________________________________________________________________________________________
## layer_3 (Dense) (None, 8) 256 third_input[0][0]
## __________________________________________________________________________________________
## dense_23 (Dense) (None, 2) 18 layer_1[0][0]
## __________________________________________________________________________________________
## dense_24 (Dense) (None, 2) 18 layer_2[0][0]
## __________________________________________________________________________________________
## dense_25 (Dense) (None, 2) 18 layer_3[0][0]
## __________________________________________________________________________________________
## concatenate (Concatenate) (None, 6) 0 dense_23[0][0]
## dense_24[0][0]
## dense_25[0][0]
## __________________________________________________________________________________________
## main_output (Dense) (None, 2) 14 concatenate[0][0]
## ==========================================================================================
## Total params: 836
## Trainable params: 836
## Non-trainable params: 0
## __________________________________________________________________________________________
model_ens %>% keras::compile( # Learning parameters
optimizer = optimizer_adam(),
loss = "binary_crossentropy",
metrics = "categorical_accuracy"
)
fit_NN_ens <- model_ens %>% fit( # Learning function
x = list(first_input = feat_train_1,
second_input = feat_train_2,
third_input = feat_train_3),
y = list(main_output = NN_train_labels_C), # Recycled from NN Chapter
epochs = 12, # Nb rounds
batch_size = 512, # Nb obs. per round
validation_data = list(list(feat_test_1, feat_test_2, feat_test_3),
NN_test_labels_C)
)
plot(fit_NN_ens)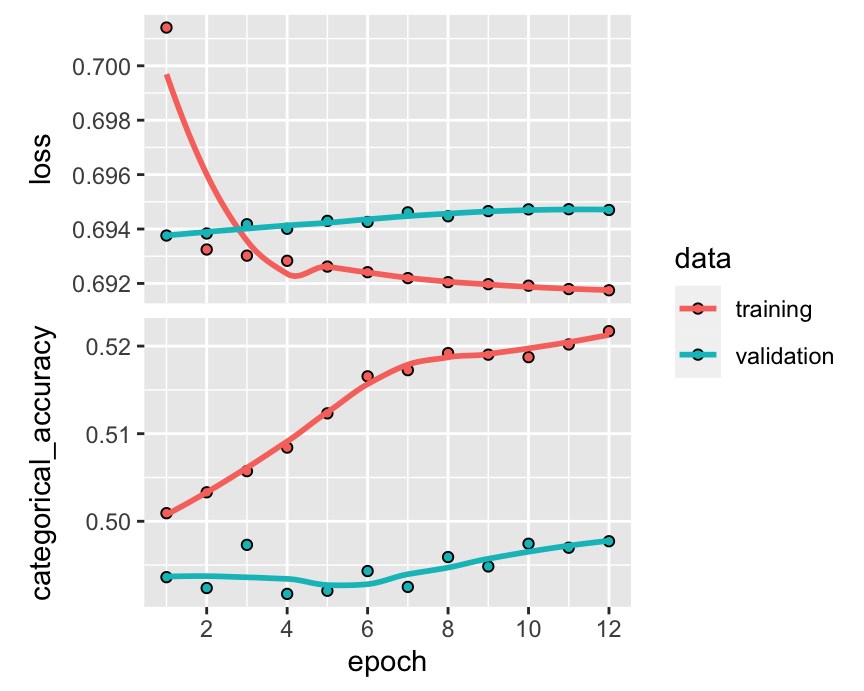
FIGURE 19.13: Learning an integrated ensemble.
19.8 Chapter 12
19.8.1 EW portfolios with the tidyverse
This one is incredibly easy; it’s simpler and more compact but close in spirit to the code that generates Figure 3.1. The returns are plotted in Figure 19.14.
data_ml %>%
group_by(date) %>% # Group by date
summarize(return = mean(R1M_Usd)) %>% # Compute return
ggplot(aes(x = date, y = return)) + geom_point() + geom_line() # Plot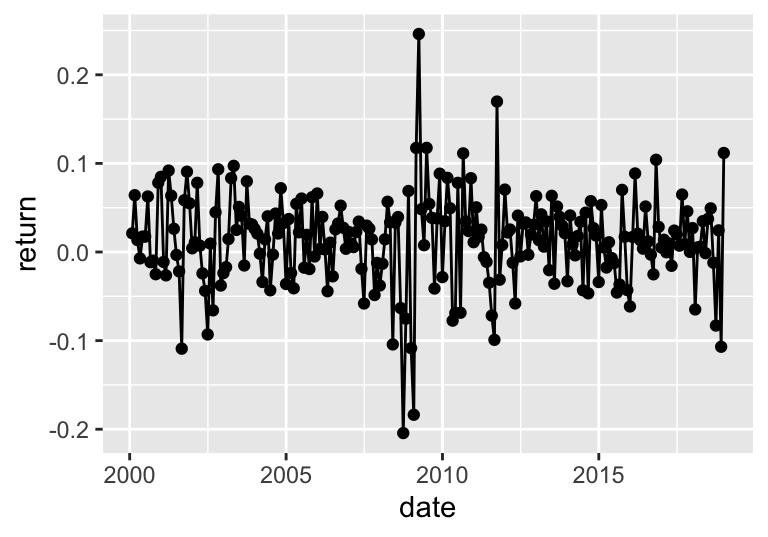
FIGURE 19.14: Time series of returns.
19.8.2 Advanced weighting function
First, we code the function with all inputs.
weights <- function(Sigma, mu, Lambda, lambda, k_D, k_R, w_old){
N <- nrow(Sigma)
M <- solve(lambda*Sigma + 2*k_R*Lambda + 2*k_D*diag(N)) # Inverse matrix
num <- 1-sum(M %*% (mu + 2*k_R*Lambda %*% w_old)) # eta numerator
den <- sum(M %*% rep(1,N)) # eta denominator
eta <- num / den # eta
vec <- mu + eta * rep(1,N) + 2*k_R*Lambda %*% w_old # Vector in weight
return(M %*% vec)
}Second, we test it on some random dataset. We use the returns created at the end of Chapter 1 and used for the Lasso allocation in Section 5.2.2. For \(\boldsymbol{\mu}\), we use the sample average, which is rarely a good idea in practice. It serves as illustration only.
Sigma <- returns %>% dplyr::select(-date) %>% as.matrix() %>% cov() # Covariance matrix
mu <- returns %>% dplyr::select(-date) %>% apply(2,mean) # Vector of exp. returns
Lambda <- diag(nrow(Sigma)) # Trans. Cost matrix
lambda <- 1 # Risk aversion
k_D <- 1
k_R <- 1
w_old <- rep(1, nrow(Sigma)) / nrow(Sigma) # Prev. weights: EW
weights(Sigma, mu, Lambda, lambda, k_D, k_R, w_old) %>% head() # First weights## [,1]
## 1 0.0031339308
## 3 -0.0003243527
## 4 0.0011944677
## 7 0.0014194215
## 9 0.0015086240
## 11 -0.0005015207Some weights can of course be negative. Finally, we use the map2() function to test some sensitivity. We examine 3 key indicators:
- diversification, which we measure via the inverse of the sum of squared weights (inverse Hirschman-Herfindhal index);
- leverage, which we assess via the absolute sum of negative weights;
- in-sample volatility, which we compute as \(\textbf{w}' \boldsymbol{\Sigma} \textbf{x}\)
To do so, we create a dedicated function below.
sensi <- function(lambda, k_D, Sigma, mu, Lambda, k_R, w_old){
w <- weights(Sigma, mu, Lambda, lambda, k_D, k_R, w_old)
out <- c()
out$div <- 1/sum(w^2) # Diversification
out$lev <- sum(abs(w[w<0])) # Leverage
out$vol <- t(w) %*% Sigma %*% w # In-sample vol
return(out)
}Instead of using the baseline map2 function, we rely on a version thereof that concatenates results into a dataframe directly.
lambda <- 10^(-3:2) # parameter values
k_D <- 2*10^(-3:2) # parameter values
pars <- expand_grid(lambda, k_D) # parameter grid
lambda <- pars$lambda
k_D <- pars$k_D
res <- map2_dfr(lambda, k_D, sensi,
Sigma = Sigma, mu = mu, Lambda = Lambda, k_R = k_R, w_old = w_old)
bind_cols(lambda = as.factor(lambda), k_D = as.factor(k_D), res) %>%
gather(key = indicator, value = value, -lambda, -k_D) %>%
ggplot(aes(x = lambda, y = value, fill = k_D)) + geom_col(position = "dodge") +
facet_grid(indicator ~. , scales = "free")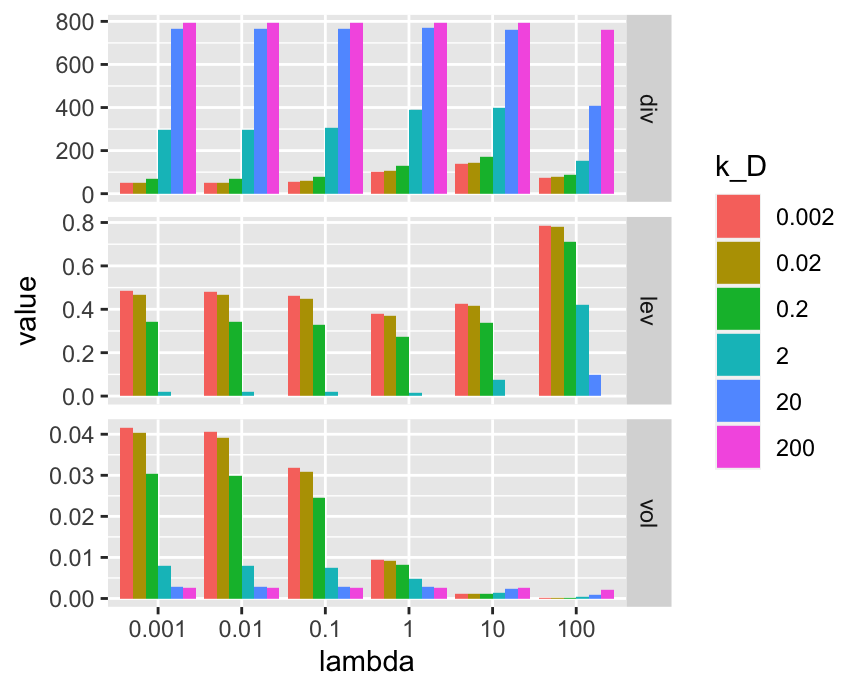
FIGURE 19.15: Indicators related to portfolio weights.
In Figure 19.15, each panel displays an indicator. In the first panel, we see that diversification increases with \(k_D\): indeed, as this number increases, the portfolio converges to uniform (EW) values. The parameter \(\lambda\) has a minor impact. The second panel naturally shows the inverse effect for leverage: as diversification increases with \(k_D\), leverage (i.e., total negative positions - shortsales) decreases. Finally, the last panel shows that in-sample volatility is however largely driven by the risk aversion parameter. As \(\lambda\) increases, volatility logically decreases. For small values of \(\lambda\), \(k_D\) is negatively related to volatility but the pattern reverses for large values of \(\lambda\). This is because the equally weighted portfolio is less risky than very leveraged mean-variance policies, but more risky than the minimum-variance portfolio.
19.8.3 Functional programming in the backtest
Often, programmers prefer to avoid loops. In order to avoid a loop in the backtest, we need to code what happens for one given date. This is encapsulated in the following function. For simplicity, we code it for only one strategy. Also, the function will assume the structure of the data is known, but the columns (features & labels) could also be passed as arguments. We recycle the function weights_xgb from Chapter 12.
portf_map <- function(t, data_ml, ticks, t_oos, m_offset, train_size, weight_func){
train_data <- data_ml %>% filter(date < t_oos[t] - m_offset * 30, # Roll. window w. buffer
date > t_oos[t] - m_offset * 30 - 365 * train_size)
test_data <- data_ml %>% filter(date == t_oos[t]) # Test set
realized_returns <- test_data %>% # Computing returns via:
dplyr::select(R1M_Usd) # 1M holding period!
temp_weights <- weight_func(train_data, test_data, features) # Weights = > recycled!
ind <- match(temp_weights$names, ticks) %>% na.omit() # Index of test assets
x <- c()
x$weights <- rep(0, length(ticks)) # Empty weights
x$weights[ind] <- temp_weights$weights # Locate weights correctly
x$returns <- sum(temp_weights$weights * realized_returns) # Compute returns
return(x)
}Next, we combine this function to map(). We only test the first 6 dates: this reduces the computation times.
back_test <- 1:3 %>% # Test on the first 100 out-of-sample dates
map(portf_map, data_ml = data_ml, ticks = ticks, t_oos = t_oos,
m_offset = 1, train_size = 5, weight_func = weights_xgb)
head(back_test[[1]]$weights) # Sample weights## [1] 0.001675042 0.000000000 0.000000000 0.001675042 0.000000000 0.001675042
back_test[[1]]$returns # Return of first period## [1] 0.0189129Each element of backtest is a list with two components: the portfolio weights and the returns. To access the data easily, functions like melt from the package reshape2 are useful.
19.9 Chapter 15
We recycle the AE model trained in Chapter 15. Strangely, building smaller models (encoder) from larger ones (AE) requires to save and then reload the weights. This creates an external file, which we call “ae_weights”. We can check that the output does have 4 columns (compressed) instead of 7 (original data).
save_model_weights_hdf5(object = ae_model,filepath ="ae_weights.hdf5", overwrite = TRUE)
encoder_model <- keras_model(inputs = input_layer, outputs = encoder)
encoder_model %>%
load_model_weights_hdf5(filepath = "ae_weights.hdf5",skip_mismatch = TRUE,by_name = TRUE)
encoder_model %>% keras::compile(
loss = 'mean_squared_error',
optimizer = 'adam',
metrics = c('mean_absolute_error')
)
encoder_model %>%
keras::predict_on_batch(x = training_sample %>%
dplyr::select(features_short) %>%
as.matrix()) %>%
head(5)## [,1] [,2] [,3] [,4]
## [1,] -0.08539051 1.200299 -0.8444785 -1.174033
## [2,] -0.06630807 1.195867 -0.8294346 -1.147886
## [3,] -0.09406579 1.194935 -0.8672158 -1.165673
## [4,] -0.09864470 1.191096 -0.8709179 -1.166036
## [5,] -0.10819313 1.173754 -0.8648338 -1.17202119.10 Chapter 16
All we need to do is change the rho coefficient in the code of Chapter 16.
set.seed(42) # Fixing the random seed
n_sample <- 10^5 # Number of samples generated
rho <- (-0.8) # Autoregressive parameter
sd <- 0.4 # Std. dev. of noise
a <- 0.06 * rho # Scaled mean of returns
data_RL3 <- tibble(returns = a/rho + arima.sim(n = n_sample, # Returns via AR(1) simulation
list(ar = rho),
sd = sd),
action = round(runif(n_sample)*4)/4) %>% # Random action (portfolio)
mutate(new_state = if_else(returns < 0, "neg", "pos"), # Coding of state
reward = returns * action, # Reward = portfolio return
state = lag(new_state), # Next state
action = as.character(action)) %>%
na.omit() # Remove one missing stateThe learning can then proceed.
control <- list(alpha = 0.1, # Learning rate
gamma = 0.7, # Discount factor for rewards
epsilon = 0.1) # Exploration rate
fit_RL3 <- ReinforcementLearning(data_RL3, # Main RL function
s = "state",
a = "action",
r = "reward",
s_new = "new_state",
control = control)
print(fit_RL3) # Show the output## State-Action function Q
## 0.25 0 1 0.75 0.5
## neg 0.7107268 0.5971710 1.4662416 0.9535698 0.8069591
## pos 0.7730842 0.7869229 0.4734467 0.4258593 0.6257039
##
## Policy
## neg pos
## "1" "0"
##
## Reward (last iteration)
## [1] 3013.162In this case, the constantly switching feature of the return process changes the outcome. The negative state is associated with large profits when the portfolio is fully invested, while the positive state has the best average reward when the agent refrains from investing.
For the second exercise, the trick is to define all possible actions, that is all combinations (+1,0-1) for the two assets on all dates. We recycle the data from Chapter 16.
pos_3 <- c(-1,0,1) # Possible alloc. to asset 1
pos_4 <- c(-1,0,1) # Possible alloc. to asset 3
pos <- expand_grid(pos_3, pos_4) # All combinations
pos <- bind_cols(pos, id = 1:nrow(pos)) # Adding combination id
ret_pb_RL <- bind_cols(r3 = return_3, r4 = return_4, # Returns & P/B dataframe
pb3 = pb_3, pb4 = pb_4)
data_RL4 <- sapply(ret_pb_RL, # Combining return & positions
rep.int,
times = nrow(pos)) %>%
data.frame() %>%
bind_cols(id = rep(1:nrow(pos), 1, each = length(return_3))) %>%
left_join(pos) %>% dplyr::select(-id) %>%
mutate(action = paste(pos_3, pos_4), # Uniting actions
pb3 = round(5 * pb3), # Simplifying states
pb4 = round(5 * pb4), # Simplifying states
state = paste(pb3, pb4), # Uniting states
reward = pos_3*r3 + pos_4*r4, # Computing rewards
new_state = lead(state)) %>% # Infer new state
dplyr::select(-pb3, -pb4, -pos_3, # Remove superfluous vars.
-pos_4, -r3, -r4) We can the plug this data into the RL function.
fit_RL4 <- ReinforcementLearning(data_RL4, # Main RL function
s = "state",
a = "action",
r = "reward",
s_new = "new_state",
control = control)
fit_RL4$Q <- round(fit_RL4$Q, 3) # Round the Q-matrix
print(fit_RL4) # Show the output ## State-Action function Q
## 0 0 0 1 0 -1 -1 -1 -1 0 -1 1 1 -1 1 0 1 1
## 0 2 0.000 0.000 0.002 -0.017 -0.018 -0.020 0.023 0.025 0.024
## 0 3 0.001 -0.005 0.007 -0.013 -0.019 -0.026 0.031 0.027 0.021
## 3 1 0.003 0.003 0.003 0.002 0.002 0.003 0.002 0.002 0.003
## 2 1 0.027 0.038 0.020 0.004 0.015 0.039 0.013 0.021 0.041
## 2 2 0.021 0.014 0.027 0.038 0.047 0.045 -0.004 -0.011 -0.016
## 2 3 0.007 0.006 0.008 0.054 0.057 0.056 -0.041 -0.041 -0.041
## 1 1 0.027 0.054 0.005 -0.031 -0.005 0.041 0.025 0.046 0.072
## 1 2 0.019 0.020 0.020 0.015 0.023 0.029 0.012 0.014 0.023
## 1 3 0.008 0.019 0.000 -0.036 -0.027 -0.016 0.042 0.053 0.060
##
## Policy
## 0 2 0 3 3 1 2 1 2 2 2 3 1 1 1 2 1 3
## "1 0" "1 -1" "0 -1" "1 1" "-1 0" "-1 0" "1 1" "-1 1" "1 1"
##
## Reward (last iteration)
## [1] 0The matrix is less sparse compared to the one of Chapter 16; we have covered much more ground! Some policy recommendations have not changed compared to the smaller sample, but some have! The change occurs for the states for which only a few points were available in the first trial. With more data, the decision is altered.
For a list of online resources, we recommend the curated page https://github.com/josephmisiti/awesome-machine-learning/blob/master/books.md.↩︎
One example: https://www.bioconductor.org/packages/release/bioc/html/Rgraphviz.html↩︎
By copy-pasting the content of the package in the library folder. To get the address of the folder, execute the command .libPaths() in the R console.↩︎
We refer to for a list of alternative data providers. Moreover, we recall that Quandl, an alt-data hub was acquired by Nasdaq in December 2018. As large players acquire newcomers, the field may consolidate.↩︎
Other approaches are nonetheless possible, as is advocated in Prado and Fabozzi (2020).↩︎
This has been a puzzle for the value factor during the 2010 decade during which the factor performed poorly (see Bellone et al. (2020) Cornell and Damodaran (2021) and Stagnol et al. (2021)). Shea and Radatz (2020) argue that it is because some fundamentals of value firms (like ROE) have not improved at the rate of those of growth firms. This underlines that it is hard to pick which fundamental metrics matter and that their importance varies with time. Binz, Schipper, and Standridge (2020) even find that resorting to AI to make sense (and mine) the fundamentals’ zoo only helps marginally.↩︎
Originally, Fama and MacBeth (1973) work with the market beta only: \(r_{t,n}=\alpha_n+\beta_nr_{t,M}+\epsilon_{t,n}\) and the second pass included nonlinear terms: \(r_{t,n}=\gamma_{n,0}+\gamma_{t,1}\hat{\beta}_{n}+\gamma_{t,2}\hat{\beta}^2_n+\gamma_{t,3}\hat{s}_n+\eta_{t,n}\), where the \(\hat{s}_n\) are risk estimates for the assets that are not related to the betas. It is then possible to perform asset pricing tests to infer some properties. For instance, test whether betas have a linear influence on returns or not (\(\mathbb{E}[\gamma_{t,2}]=0\)), or test the validity of the CAPM (which implies \(\mathbb{E}[\gamma_{t,0}]=0\)).↩︎
Older tests for the number of factors in linear models include Connor and Korajczyk (1993) and Bai and Ng (2002).↩︎
Autocorrelation in aggregate/portfolio returns is a widely documented effect since the seminal paper Lo and MacKinlay (1990) (see also Moskowitz, Ooi, and Pedersen (2012)).↩︎
In the same spirit, see also Lettau and Pelger (2020a) and Lettau and Pelger (2020b).↩︎
Some methodologies do map firm attributes into final weights, e.g., Brandt, Santa-Clara, and Valkanov (2009) and Ammann, Coqueret, and Schade (2016), but these are outside the scope of the book.↩︎
This is of course not the case for inference relying on linear models. Memory generates many problems and complicates the study of estimators. We refer to Hjalmarsson (2011) and Xu (2020) for theoretical and empirical results on this matter.↩︎
For a more thorough technical discussion on the impact of feature engineering, we refer to Galili and Meilijson (2016).↩︎
See www.kaggle.com. ↩︎
The strength is measured as the average margin, i.e. the average of \(mg\) when there is only one tree.↩︎
See, e.g., http://docs.h2o.ai/h2o/latest-stable/h2o-r/docs/reference/h2o.randomForest.html↩︎
The Real Adaboost of J. Friedman et al. (2000) has a different output: the probability of belonging to a particular class.↩︎
In case of package conflicts, use keras::get_weights(model). Indeed, another package in the machine learning landscape, yardstick, uses the function name “get_weights”.↩︎
This assumption can be relaxed, but the algorithms then become more complex and are out of the scope of the current book. One such example that generalizes the naive Bayes approach is N. Friedman, Geiger, and Goldszmidt (1997).↩︎
In the case of BARTs, the training consists exactly in the drawing of posterior samples.↩︎
There are some exceptions, like attempts to optimize more exotic criteria, such as the Spearman rho, which is based on rankings and is close in spirit to maximizing the correlation between the output and the prediction. Because this rho cannot be differentiated, this causes numerical issues. These problems can be partially alleviated when resorting to complex architectures, as in Engilberge et al. (2019). ↩︎
Another angle, critical of neural networks is provided in Geman, Bienenstock, and Doursat (1992).↩︎
Constraints often have beneficial effects on portfolio composition, see Jagannathan and Ma (2003) and DeMiguel et al. (2009).↩︎
A long position in an asset with positive return or a short position in an asset with negative return.↩︎
We invite the reader to have a look at the thoughtful albeit theoretical paper by Arjovsky et al. (2019).↩︎
In the thread https://twitter.com/fchollet/status/1177633367472259072, François Chollet, the creator of Keras argues that ML predictions based on price data cannot be profitable in the long term. Given the wide access to financial data, it is likely that the statement holds for predictions stemming from factor-related data as well.↩︎
For instance, we do not mention the work of Horel and Giesecke (2019) but the interested reader can have a look at their work on neural networks (and also at the references cited in the paper).↩︎
The CAM package was removed from CRAN in November 2019 but can still be installed manually. First, download the content of the package: https://cran.r-project.org/web/packages/CAM/index.html. Second, copy it in the directory obtained by typing .libPaths() in the console.↩︎
Another possible choice is the baycn package documented in E. A. Martin and Fu (2019).↩︎
See for instance the papers on herding in factor investing: Krkoska and Schenk-Hoppé (2019) and Santi and Zwinkels (2018).↩︎
This book is probably the most complete reference for theoretical results in machine learning, but it is in French.↩︎
In practice, this is not a major problem; since we work with features that are uniformly distributed, de-meaning amounts to remove 0.5 to all feature values.↩︎
Like neural networks, reinforcement learning methods have also been recently developed for derivatives pricing and hedging, see for instance Kolm and Ritter (2019a) and J. Du et al. (2020).↩︎
e.g., Sharpe ratio which is for instance used in Moody et al. (1998), Bertoluzzo and Corazza (2012) and Aboussalah and Lee (2020) or drawdown-based ratios, as in Almahdi and Yang (2017).↩︎
Some recent papers consider arbitrary weights (e.g., Z. Jiang, Xu, and Liang (2017) and Yu et al. (2019)) for a limited number of assets.↩︎