 FIGURE 8.1: Diagram of binary classification with support vectors.
FIGURE 8.1: Diagram of binary classification with support vectors.
While the origins of support vector machines (SVMs) are old (and go back to Vapnik and Lerner (1963)), their modern treatment was initiated in Boser, Guyon, and Vapnik (1992) and Cortes and Vapnik (1995) (binary classification) and Drucker et al. (1997) (regression). We refer to http://www.kernel-machines.org/books for an exhaustive bibliography on their theoretical and empirical properties. SVMs have been very popular since their creation among the machine learning community. Nonetheless, other tools (neural networks especially) have gained popularity and progressively replaced SVMs in many applications like computer vision notably.
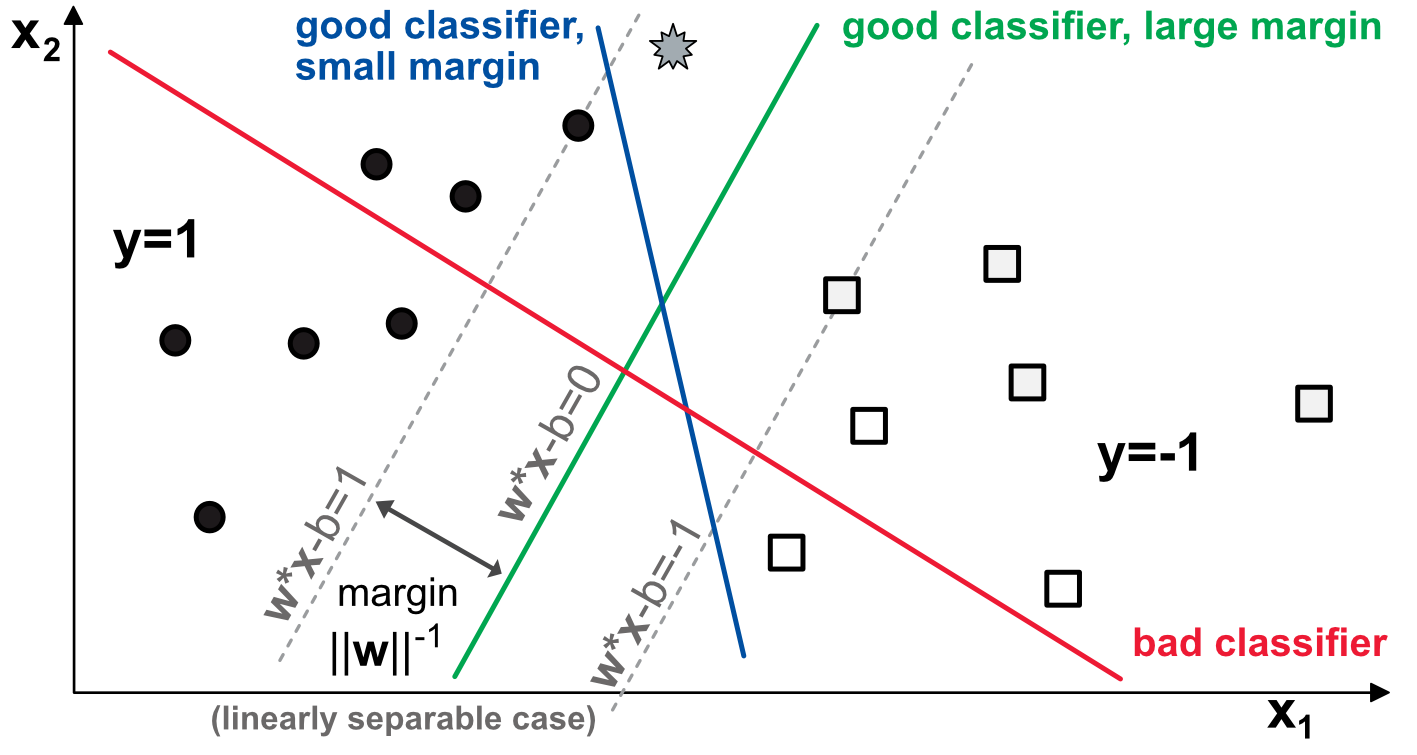
As is often the case in machine learning, it is easier to explain a complex tool through an illustration with binary classification. In fact, sometimes, it is originally how the tool was designed (e.g., for the perceptron). Let us consider a simple example in the plane, that is, with two features. In Figure 8.1, the goal is to find a model that correctly classifies points: filled circles versus empty squares.
FIGURE 8.1: Diagram of binary classification with support vectors.
A model consists of two weights $\textbf{w}=(w_1,w_2)$ that load on the variables and create a natural linear separation in the plane. In the example above, we show three separations. The red one is not a good classifier because there are circles and squares above and beneath it. The blue line is a good classifier: all circles are to its left and all squares to its right. Likewise, the green line achieves a perfect classification score. Yet, there is a notable difference between the two.
The grey star at the top of the graph is a mystery point and given its location, if the data pattern holds, it should be a circle. The blue model fails to recognize it as such while the green one succeeds. The interesting features of the scheme are those that we have not mentioned yet, that is, the grey dotted lines. These lines represent the no-man’s land in which no observation falls when the green model is enforced. In this area, each strip above and below the green line can be viewed as a margin of error for the model. Typically, the grey star is located inside this margin.
The two margins are computed as the parallel lines that maximize the distance between the model and the closest points that are correctly classified (on both sides). These points are called support vectors, which justifies the name of the technique. Obviously, the green model has a greater margin than the blue one. The core idea of SVMs is to maximize the margin, under the constraint that the classifier does not make any mistake. Said differently, SVMs try to pick the most robust model among all those that yield a correct classification.
More formally, if we numerically define circles as +1 and squares as -1, any ‘good’ linear model is expected to satisfy:
which can be summarized in compact form $y_i \times \left(\sum_{k=1}^K w_kx_{i,k}+b \right)\ge 1$. Now, the margin between the green model and a support vector on the dashed grey line is equal to $||\textbf{w}||^{-1}=\left(\sum_{k=1}^Kw_k^2\right)^{-1/2}$. This value comes from the fact that the distance between a point $(x_0,y_0)$ and a line parametrized by $ax+by+c=0$ is equal to $d=\frac{|ax_0+by_0+c|}{\sqrt{a^2+b^2}}$. In the case of the model defined above (8.1), the numerator is equal to 1 and the norm is that of $\textbf{w}$ . Thus, the final problem is the following:
The dual form of this program (see chapter 5 in Boyd and Vandenberghe (2004)) is
The dual form of this program (see chapter 5 in Boyd and Vandenberghe (2004)) is
where either $\lambda_i=0$ or $y_i\left(\sum_{k=1}^Kw_kx_{i,k}+b \right)= 1$. Thus, only some points will matter in the solution (the so-called support vectors). The first order conditions impose that the derivatives of this Lagrangian be null:
where the first condition leads to
This solution is indeed a linear form of the features, but only some points are taken into account. They are those for which the inequalities (8.1) are equalities.
Naturally, this problem becomes infeasible whenever the condition cannot be satisfied, that is, when a simple line cannot perfectly separate the labels, no matter the choice of coefficients. This is the most common configuration and datasets are then called logically not linearly separable. This complicates the process but it is possible to resort to a trick. The idea is to introduce some flexbility in (8.1) by adding correction variables that allow the conditions to be met:
where the novelties, the $\xi_i$ are positive so-called ‘slack’ variables that make the conditions feasible. They are illustrated in Figure 8.2. In this new configuration, there is no simple linear model that can perfectly discriminate between the two classes.
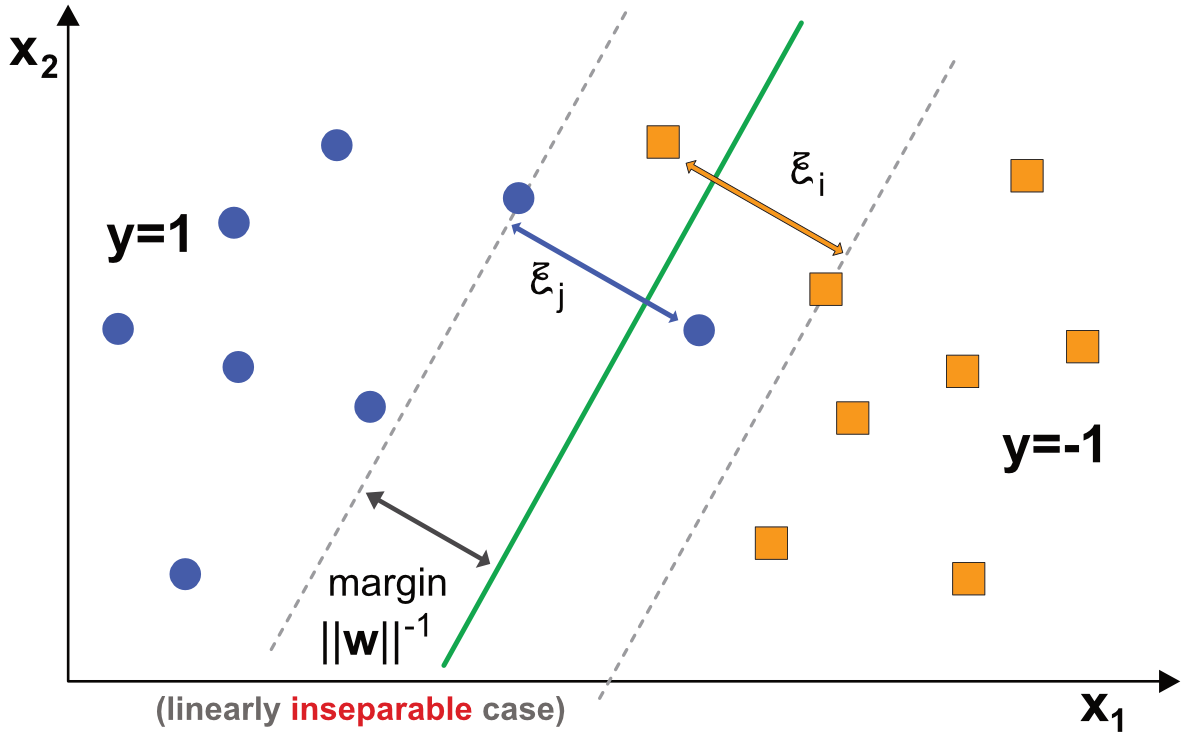 FIGURE 8.2: Diagram of binary classification with SVM - linearly inseparable data.
FIGURE 8.2: Diagram of binary classification with SVM - linearly inseparable data.
The optimization program then becomes
where the parameter $C>0$ tunes the cost of mis-classification: as $C$ increases, errors become more penalizing.
In addition, the program can be generalized to nonlinear models, via the kernel $\phi$ which is applied to the input points $x_{i,k}$. Nonlinear kernels can help cope with patterns that are more complex than straight lines (see Figure 8.3). Common kernels can be polynomial, radial or sigmoid. The solution is found using more or less standard techniques for constrained quadratic programs. Once the weights $\textbf{w}$ and bias $b$ are set via training, a prediction for a new vector $textbf{x}_j$ is simply made by computing $\sum_{k=1}^Kw_k\phi(x_{j,k})+b$ and choosing the class based on the sign of the expression.
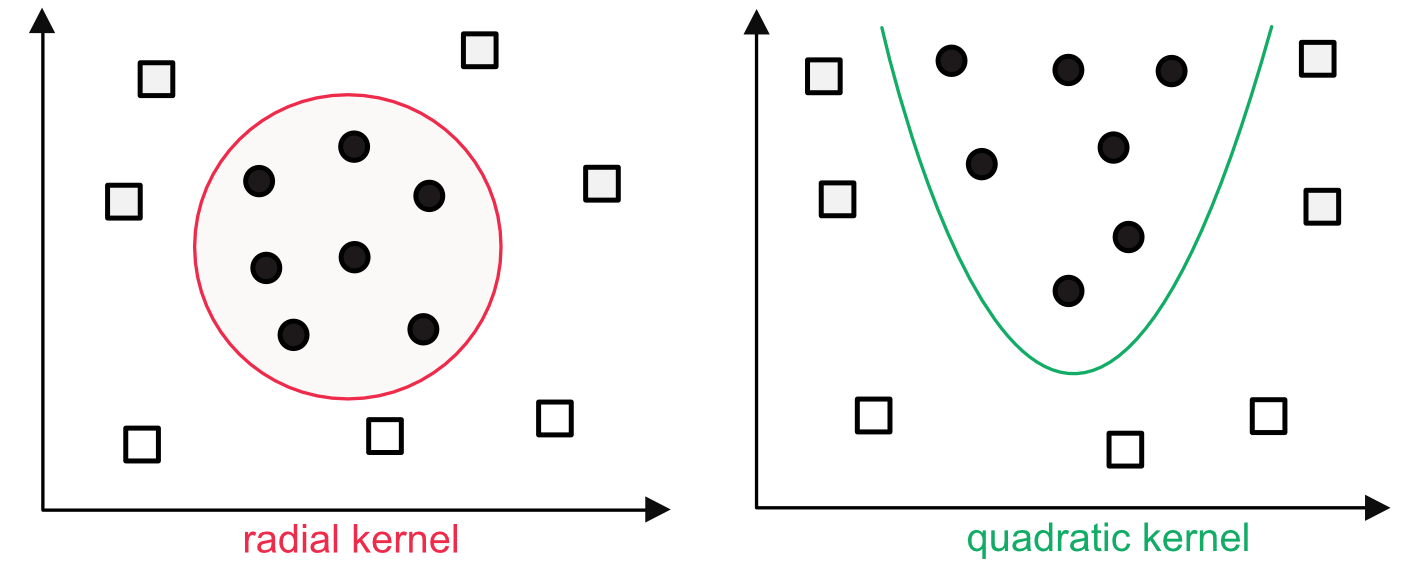 FIGURE 8.3: Examples of nonlinear kernels.
FIGURE 8.3: Examples of nonlinear kernels.
The ideas of classification SVM can be transposed to regression exercises but the role of the margin is different. One general formulation is the following
and it is illustrated in Figure 8.4. The user specifies a margin $\epsilon$ and the model will try to find the linear (up to kernel transformation) relationship between the labels $y_1$ and the input $\textbf{x}_i$. Just as in the classification task, if the data points are inside the strip, the slack variables $\xi_i$ and $\xi_i^*$ are set to zero. When the points violate the threshold, the objective function (first line of the code) is penalized. Note that setting a large $\epsilon$ leaves room for more error. Once the model has been trained, a prediction for $\textbf{x}_j$ is simply $\sum_{k=1}^Kw_k\phi(x_{j,k})+b$.
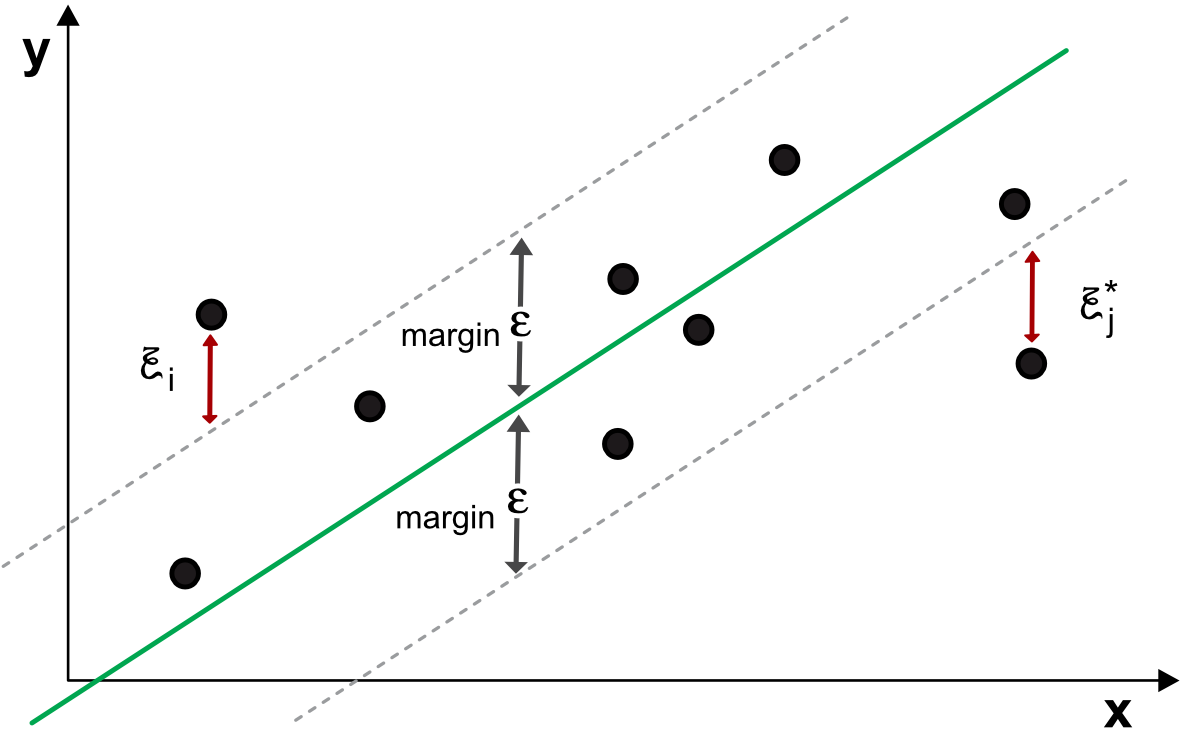 FIGURE 8.4: Diagram of regression SVM.
FIGURE 8.4: Diagram of regression SVM.
Let us take a step back and simplify what the algorithm does, that is: minimize the sum of squared weights $||\textbf{w}||^2$ subject to the error being small enough (modulo a slack variable). In spirit, this somewhat the opposite of the penalized linear regressions which seek to minimize the error, subject to the weights being small enough.
The models laid out in this section are a preview of the universe of SVM engines and several other formulations have been developed. One reference library that is coded in C and C++ is LIBSVM and it is widely used by many other programming languages. The interested reader can have a look at the corresponding article Chang and Lin (2011) for more details on the SVM zoo (a more recent November 2019 version is also available online).
For the sake of consistency we will use scikit-learn's implementation of SVM in the following code snippets. In the implementation of LIBSVM, the package requires to specify the label and features separately. For this reason, we recycle the variables used for the boosted trees. Moreover, the training being slow, we perform it on a subsample of these sets (first thousand instances).
from sklearn import svm
# recall of some variables
y = train_label_xgb.iloc[0:1000] # Train label
x = train_features_xgb.iloc[0:1000,] # Training features
test_feat_short=testing_sample[features_short]
y_c=train_label_xgb_C.iloc[0:1000] # Dependent variable
model_svm=svm.SVR(
kernel='rbf', # SVM kernel (or: linear, polynomial, sigmoid)
C=0.1, # Slack variable penalisation
epsilon=0.1, # Width of strip for errors
gamma=0.5 # Constant in the radial kernel
)
fit_svm=model_svm.fit(x, y) # Fitting the model
mse = np.mean((fit_svm.predict(test_feat_short) - y_test)**2)
print(f'MSE: {mse}')
MSE: 0.04226507027049866
hitratio = np.mean(fit_svm.predict(test_feat_short) * y_test > 0)
print(f'Hit Ratio: {hitratio}')
Hit Ratio: 0.4678811531449407
The results are lower than those of the boosted trees. All parameters are completely arbitrary, especially the choice of the kernel. We finally turn to a classification example.
model_svm_c=svm.SVC(
kernel='sigmoid',
C=0.2, # Slack variable penalisation
gamma=0.5, # Parameter in the sigmoid kernel
coef0=0.3 # Parameter in the sigmoid kernel
)
fit_svm_c=model_svm_c.fit(x,y_c) # Fitting the model
hitratio = np.mean(fit_svm_c.predict(test_feat_short) == y_c_test)
print(f'Hit Ratio: {hitratio}')
Hit Ratio: 0.49082725615314493
Both the small training sample and the arbitrariness in our choice of the parameters may explain why the predictive accuracy is so poor.
Boser, Bernhard E, Isabelle M Guyon, and Vladimir N Vapnik. 1992. “A Training Algorithm for Optimal Margin Classifiers.” In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, 144–52. ACM.
Boyd, Stephen, and Lieven Vandenberghe. 2004. Convex Optimization. Cambridge University Press.
Chang, Chih-Chung, and Chih-Jen Lin. 2011. “LIBSVM: A Library for Support Vector Machines.” ACM Transactions on Intelligent Systems and Technology (TIST) 2 (3): 27.
Cortes, Corinna, and Vladimir Vapnik. 1995. “Support-Vector Networks.” Machine Learning 20 (3): 273–97.
Drucker, Harris, Christopher JC Burges, Linda Kaufman, Alex J Smola, and Vladimir Vapnik. 1997. “Support Vector Regression Machines.” In Advances in Neural Information Processing Systems, 155–61.
Vapnik, Vladimir, and A. Lerner. 1963. “Pattern Recognition Using Generalized Portrait Method.” Automation and Remote Control 24: 774–80.