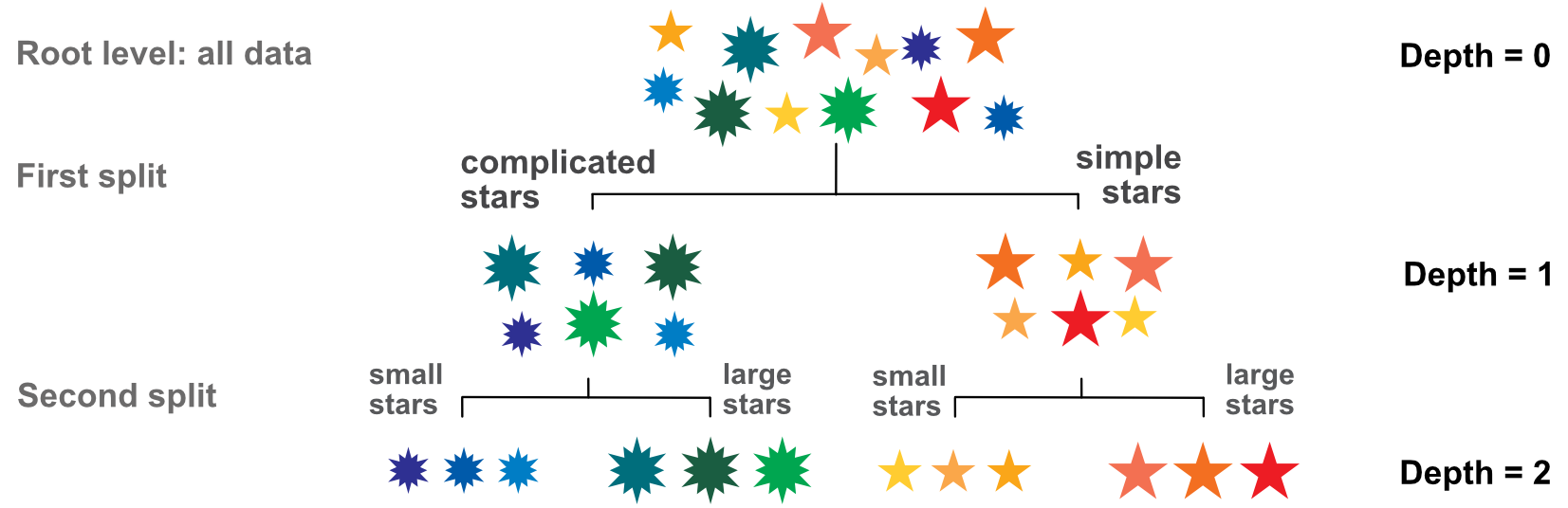
 FIGURE 6.1: Elementary tree scheme; visualization of the splitting process.
FIGURE 6.1: Elementary tree scheme; visualization of the splitting process.
Classification and regression trees are simple yet powerful clustering algorithms popularized by the monograph of Breiman et al. (1984). Decision trees and their extensions are known to be quite efficient forecasting tools when working on tabular data. A large proportion of winning solutions in ML contests (especially on the Kaggle website$^{13}$) resort to improvements of simple trees. For instance, the meta-study in bioinformatics by Olson et al. (2018) finds that boosted trees and random forests are the top 2 algorithms from a group of 13, excluding neural networks.
Recently, the surge in Machine Learning applications in Finance has led to multiple publications that use trees in portfolio allocation problems. A long, though not exhaustive, list includes: Ballings et al. (2015), Patel, Shah, Thakkar, and Kotecha (2015a), Patel, Shah, Thakkar, and Kotecha (2015b), Moritz and Zimmermann (2016), Krauss, Do, and Huck (2017), Gu, Kelly, and Xiu (2020b), Guida and Coqueret (2018a), Coqueret and Guida (2020) and Simonian et al. (2019). One notable contribution is Bryzgalova, Pelger, and Zhu (2019) in which the authors create factors from trees by sorting portfolios via simple trees, which they call Asset Pricing Trees.
In this chapter, we review the methodologies associated to trees and their applications in portfolio choice.
Decision trees seek to partition datasets into homogeneous clusters. Given an exogenous variable $\mathbf{Y}$ and features $\mathbf{X}$, trees iteratively split the sample into groups (usually two at a time) which are as homogeneous in $\mathbf{Y}$ as possible. The splits are made according to one variable within the set of features. A short word on nomenclature: when $\mathbf{Y}$ consists of real numbers, we talk about regression trees and when $\mathbf{Y}$ is categorical, we use the term classification trees.
Before formalising this idea, we illustrate this process in Figure 6.1. There are 12 stars with three features: color, size and complexity (number of branches).
FIGURE 6.1: Elementary tree scheme; visualization of the splitting process.
The dependent variable is the color (let’s consider the wavelength associated to the color for simplicity). The first split is made according to size or complexity. Clearly, complexity is the better choice: complicated stars are blue and green, while simple stars are yellow, orange and red. Splitting according to size would have mixed blue and yellow stars (small ones) and green and orange stars (large ones).
The second step is to split the two clusters one level further. Since only one variable (size) is relevant, the secondary splits are straightforward. In the end, our stylized tree has four consistent clusters. The analogy with factor investing is simple: the color represents performance: red for high performance and blue for mediocre performance. The features (size and complexity of stars) are replaced by firm-specific attributes, such as capitalization, accounting ratios, etc. Hence, the purpose of the exercise is to find the characteristics that allow to split firms into the ones that will perform well versus those likely to fare more poorly.
We now turn to the technical construction of regression trees (splitting process). We follow the standard literature as exposed in Breiman et al. (1984) or in chapter 9 of Hastie, Tibshirani, and Friedman (2009). Given a sample of ($y_i$,$\mathbf{x}_i$) of size $I$, a regression tree seeks the splitting points that minimize the total variation of the $y_i$ inside the two child clusters. These two clusters need not have the same size. In order to do that, it proceeds in two steps. First, it finds, for each feature $x_i^{(k)}$, the best splitting point (so that the clusters are homogeneous in $\mathbf{Y}$ ). Second, it selects the feature that achieves the highest level of homogeneity.
Homogeneity in regression trees is closely linked to variance. Since we want the $y_i$ inside each cluster to be similar, we seek to minimize their variability (or dispersion) inside each cluster and then sum the two figures. We cannot sum the variances because this would not take into account the relative sizes of clusters. Hence, we work with total variation, which is the variance times the number of elements in the clusters.
Below, the notation is a bit heavy because we resort to superscripts k (the index of the feature), but it is largely possible to ignore these superscripts to ease understanding. The first step is to find the best split for each feature, that is, solve $\underset{c^{(k)}}{\text{argmin}} \ V^{(k)}_I(c^{(k)})$ with
where
are the average values of $Y$, conditional on $X^{(k)}$ being smaller or larger than $c$. The cardinal function $\#\{\cdot\}$ counts the number of instances of its argument. For feature $k$, the optimal split $c^{k,*}$ is thus the one for which the total dispersion over the two subgroups is the smallest.
The optimal splits satisfy $c^{k,*}= \underset{c^{(k)}}{\text{argmin}} \ V^{(k)}_I(c^{(k)})$ Of all the possible splitting variables, the tree will choose the one that minimizes the total dispersion not only over all splits, but also over all variables:
After one split is performed, the procedure continues on the two newly formed clusters. There are several criteria that can determine when to stop the splitting process (see Section 6.1.3). One simple criterion is to fix a maximum number of levels (the depth) for the tree. A usual condition is to impose a minimum gain that is expected for each split. If the reduction in dispersion after the split is only marginal and below a specified threshold, then the split is not executed. For further technical discussions on decision trees, we refer for instance to section 9.2.4 of Hastie, Tibshirani, and Friedman (2009).
When the tree is built (trained), a prediction for new instances is easy to make. Given its feature values, the instance ends up in one leaf of the tree. Each leaf has an average value for the label: this is the predicted outcome. Of course, this only works when the label is numerical. We discuss below the changes that occur when it is categorical.
Classification exercises are somewhat more complex than regression tasks. The most obvious difference is the measure of dispersion or heterogeneity. This loss function which must take into account the fact that the final output is not a simple number, but a vector. The output $\tilde{\textbf{y}}_i$ has as many elements as there are categories in the label and each element is the probability that the instance belong to the corresponding category.
For instance, if there are 3 categories: buy, hold and sell, then each instance would have a label with as many columns as there are classes. Following our example, one label would be (1,0,0) for a buy position for instance. We refer to Section 4.5.2 for a introduction on this topic.
Inside a tree, labels are aggregated at each cluster level. A typical output would look like (0.6,0.1,0.3): they are the proportions of each class represented within the cluster. In this case, the cluster has 60% of buy, 10% of hold and 30% of sell.
The loss function must take into account this multidimensionality of the label. When building trees, since the aim is to favor homogeneity, the loss penalizes outputs that are not concentrated towards one class. Indeed, facing a diversified output of (0.3,0.4,0.3) is much harder to handle than the concentrated case of (0.8,0.1,0.1).
The algorithm is thus seeking purity: it searches a splitting criterion that will lead to clusters that are as pure as possible, i.e., with one very dominant class, or at least just few dominant classes. There are several metrics proposed by the literature and all are based on the proportions generated by the output. If there are $J$ classes, we denote these proportions with $p_j$ . For each leaf, the usual loss functions are:
The Gini index is nothing but one minus the Herfindahl index which measures the diversification of a portfolio. Trees seek partitions that are the least diversified. The minimum value of the Gini index is zero and reached when one
$ p_j=1 $ and all others are equal to zero. The maximum value is equal to $ 1-1/J$ and is reached when all $ p_j=1/J $
. Similar relationships hold for the other two losses. One drawback of the misclassification error is its lack of differentiability which explains why the other two options are often favored.
Once the tree is grown, new instances automatically belong to one final leaf. This leaf is associated to the proportions of classes it nests. Usually, to make a prediction, the class with highest proportion (or probability) is chosen when a new instance is associated with the leaf.
When building a tree, the splitting process can be pursued until the full tree is grown, that is, when:
At this stage, the splitting process cannot be pursued.
Obviously, fully grown trees often lead to almost perfect fits when the predictors are relevant, numerous and numerical. Nonetheless, the fine grained idiosyncrasies of the training sample are of little interest for out-of-sample predictions. For instance, being able to perfectly match the patterns of 2000 to 2006 will probably not be very interesting in the period from 2007 to 2009. The most reliable sections of the trees are those closest to the root because they embed large portions of the data: the average values in the early clusters are trustworthy because the are computed on a large number of observations. The first splits are those that matter the most because they highlight the most general patterns. The deepest splits only deal with the peculiarities of the sample.
Thus, it is imperative to limit the size of the tree. There are several ways to prune the tree and all depend on some particular criteria. We list a few of them below:
In the example below, we implement all of these criteria at the same time, but usually, two of them at most should suffice.
We start with a simple tree and its interpretation. We use the package rpart and its plotting engine rpart.plot. The label is the future 1 month return and the features are all predictors available in the sample. The tree is trained on the full sample.
from sklearn import tree # Tree module
import matplotlib.pyplot as plt # to adjust tree plot
X = data_ml.iloc[:,3:96] # recall features/predictors, full sample
y = data_ml['R1M_Usd'] # recall label/Dependent variable, full sample
fit_tree = tree.DecisionTreeRegressor( # Definining the model
min_samples_split = 8000, # Min nb of obs required to continue splitting
max_depth = 3, # Maximum depth (i.e. tree levels)
ccp_alpha=0.000001, # complexity parameters
min_samples_leaf =3500 # Min nb of obs required in each terminal node (leaf)
)
fit_tree.fit(X, y) # Fitting the model
fig, ax = plt.subplots(figsize=(13, 8)) # resizing
tree.plot_tree(fit_tree,feature_names=X.columns.values, ax=ax) # Plot the tree
plt.show()

FIGURE 6.2: Simple characteristics-based tree. The dependent variable is the 1 month future return.
There usually exists a convention in the representation of trees. At each node, a condition describes the split with a boolean expression. If the expression is true, then the instance goes to the left cluster, if not, it goes to the right cluster. Given the whole sample, the initial split in this tree (Figure 6.2) is performed according to the price-to-book ratio. If the Pb score (or value) of the instance is above 0.025, then the instance is placed in the left bucket, otherwise, it goes in the right bucket.
At each node, there are two important metrics. The first one is the average value of the label in the cluster and the second one is the proportion of instances in the cluster. At the top of the tree, all instances (100%) are present and the average 1 month future return is 1.3%. One level below, the left cluster is by far the most crowded, with roughly 98% of observations averaging a 1.2% return. The right cluster is much smaller (2%) but concentrates instances with a much higher average return (5.9%). This is possibly an idiosyncracy of the sample.
The splitting process continues similarly at each node until some condition is satisfied (typically here: the maximum depth is reached). A color codes the average return: from white (low return) to blue (high return). The leftmost cluster with the lowest average return consists of firms that satisfy all the following criteria:
have a Pb score above 0.025; have a 3 month market capitalization score above 0.16; have a score of average daily volume over the past 3 months above 0.085. Notice that one peculiarity of trees is their possible heterogeneity in cluster sizes. Sometimes, a few clusters gather almost all of the observations while a few small groups embed some outliers. This is not a favorable property of trees as small groups are more likely to be flukes and may fail to generalize out-of-sample.
This is why we imposed restrictions during the construction of the tree. The first one (minbucket = 3500 in the code) imposes that each cluster consists of at least 3500 instances. The second one (minsplit) further imposes that a cluster comprises at least 8000 observations in order to pursue the splitting process. These values logically depend on the size of the training sample. The cp = 0.0001 parameter in the code requires any split to reduce the loss below 0.9999 times its original value before the split. Finally, the maximum depth of three essentially means that there are at most three splits between the root of the tree and any terminal leaf.
The complexity of the tree (measured by the number of terminal leaves) is a decreasing function of minbucket, minsplit and cp and an increasing function of maximum depth.
Once the model has be trained (i.e., the tree is grown), a prediction for any instance is the average value of the label within the cluster where the instance should land.
y_pred=fit_tree.predict(X.iloc[0:6,:]) # Test (prediction) on the first six instances of the sample
print(f'y_pred: {y_pred}')
y_pred: [0.01088066 0.01088066 0.01088066 0.01088066 0.01088066 0.01088066]
Given the figure, we immediately conclude that these first six instances all belong to the second cluster (starting from the left).
As a verification of the first splits, we plot the smoothed average of future returns, conditionally on market capitalization, past return and trading volume.
import seaborn as sns
unpivoted_data_ml = pd.melt(data_ml[['R1M_Usd','Mkt_Cap_12M_Usd','Pb','Advt_3M_Usd']], id_vars='R1M_Usd') # selecting and putting in vector
sns.lineplot(data = unpivoted_data_ml, y='R1M_Usd', x='value', hue='variable'); # Plot from seaborn

FIGURE 6.3: Average of 1 month future returns, conditionally on market capitalization, price-to-book and volume scores
The graph shows the relevance of clusters based on market capitalizations and price-to-book ratios. For low score values of these two features, the average return is high (close to +4% on a monthly basis on the left of the curves). The pattern is more pronounced compared to volume for instance.
Finally, we assess the predictive quality of a single tree on the testing set (the tree is grown on the training set). We use a deeper tree, with a maximum depth of five.
y_train = training_sample['R1M_Usd'].values # recall features/predictors, full sample
X_train = training_sample[features].values # recall label/Dependent variable, full sample
fit_tree2 = tree.DecisionTreeRegressor( # Definining the model
min_samples_split = 4000, # Min nb of obs required to continue splitting
max_depth = 5, # Maximum depth (i.e. tree levels)
ccp_alpha=0.0001, # complexity parameters
min_samples_leaf =1500 # Min nb of obs required in each terminal node (leaf)
)
fit_tree2 = fit_tree2.fit(X_train, y_train) # Fitting the model
mse = np.mean((fit_tree2.predict(X_test) - y_test)**2)
print(f'MSE: {mse}')
MSE: 0.03699695809185004
Transforming the average results into hit ratio
hitratio = np.mean(fit_tree2.predict(X_test) * y_test > 0)
print(f'Hit Ratio: {hitratio}')
Hit Ratio: 0.5460346399270738
The mean squared error is usually hard to interpret. It’s not easy to map an error on returns into the impact on investment decisions. The hit ratio is a more intuitive indicator because it evaluates the proportion of correct guesses (and hence profitable investments). Obviously, it is not perfect: 55% of small gains can be mitigated by 45% of large losses. Nonetheless, it is a popular metric and moreover it corresponds to the usual accuracy measure often computed in binary classification exercises. Here, an accuracy of 0.546 is satisfactory. Even if any number above 50% may seem valuable, it must not be forgottent that transaction costs will curtail benefits. Hence, the benchmark threshold is probably at least at 52%.
While trees give intuitive representations of relationships between $\mathbf{Y}$ and $\mathbf{X}$, they can be improved via the simple idea of ensembles in which predicting tools are combined (this topic of model aggregation is discussed both more generally and in more details in Chapter 11).
Most of the time, when having several modelling options at hand, it is not obvious upfront which individual model is the best, hence a combination seems a reasonable path towards the diversification of prediction errors (when they are not too correlated). Some theoretical foundations of model diversification were laid out in Schapire (1990).
More practical considerations were proposed later in Ho (1995) and more importantly in Breiman (2001) which is the major reference for random forests. Bagging is successfully used in Yin (2020) to aggregate equity forecasts. There are two ways to create multiple predictors from simple trees, and random forests combine both:
Hence, it becomes simple to grow many different trees and the ensemble is simply a weighted combination of all trees. Usually, equal weights are used, which is an agnostic and robust choice. We illustrate the idea of simple combinations (also referred to as bagging) in Figure 6.4 below. The terminal prediction is simply the mean of all intermediate predictions.
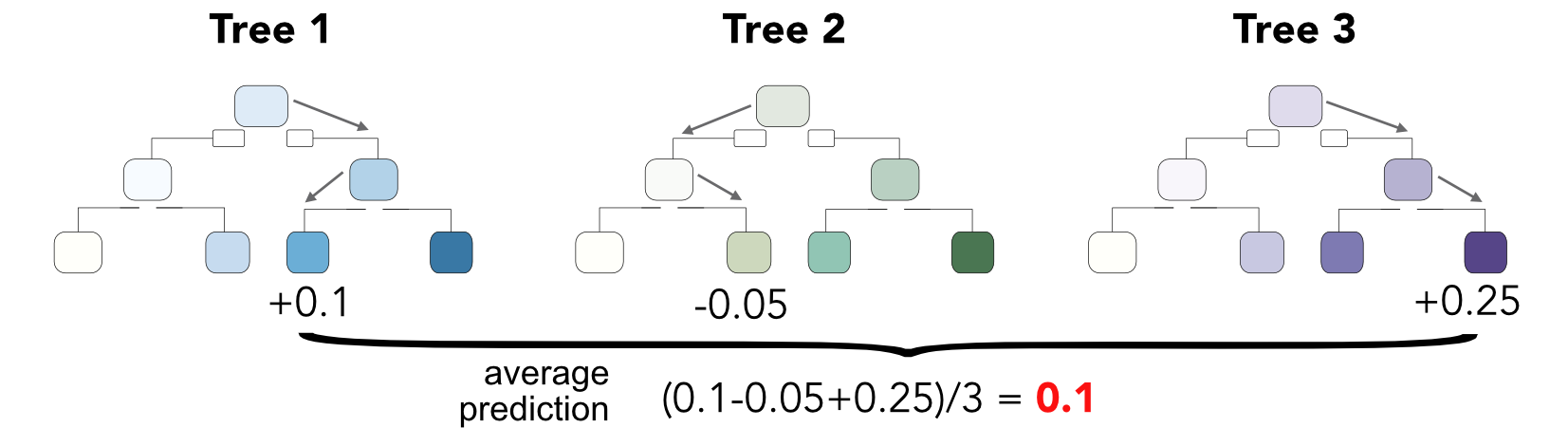 FIGURE 6.4: Combining tree outputs via random forests.
FIGURE 6.4: Combining tree outputs via random forests.
Random forests, because they are built on the idea of bootstrapping, are more efficient than simple trees. They are used by Ballings et al. (2015), Patel, Shah, Thakkar, and Kotecha (2015a), Krauss, Do, and Huck (2017), and Huck (2019) and they are shown to perform very well in these papers. The original theoretical properties of random forests are demonstrated in Breiman (2001) for classification trees. In classification exercises, the decision is taken by a vote: each tree votes for a particular class and the class with the most votes wins (with possible random picks in case of ties). Breiman (2001) defines the margin function as
$mg=M^{-1}\sum_{m=1}^M1_{\{h_m(\textbf{x})=y\}}-\max_{j\neq y}\left(M^{-1}\sum_{m=1}^M1_{\{h_m(\textbf{x})=j\}}\right),$
where the left part is the average number of votes based on the
$ M $ trees $ h_m $ for the correct class (the models $h_m$ based on $x$ matches the data value $y$). The right part is the maximum average for any other class. The margin reflects the confidence that the aggregate forest will classify properly. The generalization error is the probability that
$mg$ is strictly negative. Breiman (2001) shows that the inaccuracy of the aggregation (as measured by generalization error) is bounded by $ \bar{\rho}(1-s^2)/s^2$ , where
$s$ is the strength (average quality) of the individual classifiers and
$ρ$ is the average correlation between the learners.
Notably, Breiman (2001) also shows that as the number of trees grows to infinity, the inaccuracy converges to some finite number which explains why random forests are not prone to overfitting.
While the original paper of Breiman (2001) is dedicated to classification models, many articles have since then tackled the problem of regression trees. We refer the interested reader to Biau (2012) and to Scornet et al. (2015). Finally, further results on classifying ensembles can be obtained in Biau, Devroye, and Lugosi (2008) and we mention the short survey paper Denil, Matheson, and De Freitas (2014) which sums up recent results in this field.
Several implementations of random forests exist. For simplicity, we choose to work with the one in scikit-learn library, but there are other choices. The syntax of randomForest follows that of many ML libraries. The full list of options for some random forest implementations is prohibitively large. Below, we train a model and exhibit the predictions for the first 5 instances of the testing sample.
from sklearn.ensemble import RandomForestRegressor
fit_RF = RandomForestRegressor(n_estimators = 40, # Nb of random trees
criterion ='mse', # function to measure the quality of a split
min_samples_split= 250, # Minimum size of terminal cluster
bootstrap=False, # replacement
max_features=30, # Nb of predictive variables for each tree
max_samples=10000 # Size of (random) sample for each tree
)
fit_RF.fit(X_train, y_train) # Fitting the model
fit_RF.predict(pd.DataFrame(X_test).iloc[0:5,]) # Prediction over the first 5 test instances
array([ 0.00139083, 0.02137373, 0.04259802, -0.01310026, 0.00028897])
One first comment is that each instance has its own prediction, which contrasts with the outcome of simple tree-based outcomes. Combining many trees leads to tailored forecasts. Note that the second line of the chunk freezes the random number generation. Indeed, random forests are by construction contingent on the arbitrary combinations of instances and features that are chosen to build the individual learners.
In the above example, each individual learner (tree) is built on 10,000 randomly chosen instances (without replacement) and each terminal leaf (cluster) must comprise at least 250 elements (observations). In total, 40 trees are aggregated and each tree is constructed based on 30 randomly chosen predictors (out of the whole set of features).
Unlike for simple trees, it is not possible to simply illustrate the outcome of the learning process. It could be possible to extract all 40 trees but a synthetic visualization is out-of-reach. A simplified view can be obtained via variable importance, as is discussed in Section 13.1.2.
Finally, we can assess the accuracy of the model.
from sklearn.metrics import mean_squared_error
mse=mean_squared_error(y_test, fit_RF.predict(X_test))
print(f'MSE: {mse}')
MSE: 0.03686227217696956
hitratio = np.mean(fit_RF.predict(X_test) * y_test > 0)
print(f'Hit Ratio: {hitratio}')
Hit Ratio: 0.5320476298997265
The MSE is smaller than 4% and the hit ratio is higher than 53%, which is reasonably above both 50% and 52% thresholds.
Let’s see if we can improve the hit ratio by resorting to a classification exercise. We start by training the model on a new formula (the label is R1M_Usd_C).
from sklearn.ensemble import RandomForestClassifier
fit_RF_C = RandomForestClassifier(
n_estimators = 40, # Nb of random trees
criterion ='gini', # function to measure the quality of a split
min_samples_split= 250, # Minimum size of terminal cluster
bootstrap=False, # replacement
max_features=30, # Nb of predictive variables for each tree
max_samples=20000 # Size of (random) sample for each tree
)
fit_RF_C=fit_RF_C.fit(X_train, y_c_train) # Fitting the model
We can then assess the proportion of correct (binary) guesses.
hitratio = np.mean(fit_RF_C.predict(X_test) == y_c_test)
print(f'Hit Ratio: {hitratio}')
Hit Ratio: 0.5030480856882407
The accuracy is disappointing. There are two potential explanations for this (beyond the possibility of very different patterns in the training and testing sets). The first one is the sample size, which may be too small. The original training set has more than 200,000 observations, hence we retain only one in 10 in the above training specification. We are thus probably sidelining relevant information and the cost can be heavy. The second reason is the number of predictors, which is set to 30, i.e., one third of the total at our disposal. Unfortunately, this leaves room for the algorithm to pick less pertinent predictors. The default numbers of predictors chosen by the routines are $\sqrt{p}$ and $p/3$ for classification and regression tasks, respectively. Here $p$ is the total number of features.
The idea of boosting is slightly more advanced compared to agnostic aggregation. In random forest, we hope that the diversification through many trees will improve the overall quality of the model. In boosting, it is sought to iteratively improve the model whenever a new tree is added. There are many ways to boost learning and we present two that can easily be implemented with trees. The first one (Adaboost, for adaptive boosting) improves the learning process by progressively focusing on the instances that yield the largest errors. The second one (xgboost) is a flexible algorithm in which each new tree is only focused on the minimization of the training sample loss.
The origins of adaboost go back to Freund and Schapire (1997), Freund and Schapire (1996) and for the sake of completeness, we also mention the book dedicated on boosting Schapire and Freund (2012). Extensions of these ideas are proposed in Friedman et al. (2000) (the so-called real Adaboost algorithm) and in Drucker (1997) (for regression analysis). Theoretical treatments were derived by Breiman and others (2004).
We start by directly stating the general structure of the algorithm:
Let us comment on the steps of the algorithm. The formulation holds for many variations of Adaboost and we will specify the functions $fa$ and $fw$ below.
| Bin. classif. (orig. Adaboost) | Regression (Drucker (1997)) | |||||
|---|---|---|---|---|---|---|
| Individual error | $\epsilon_i=\textbf{1}_{\left\{y_i\neq l_m(\textbf{x}_i) \right\}}$ | $\epsilon_i=\frac{ | y_i- l_m(\textbf{x}_i) | }{\underset{i}{\max} | y_i- l_m(\textbf{x}_i) | }$ |
| Weight of learner via $f_a$ | $f_a=\log\left(\frac{1-\epsilon}{\epsilon} \right)$,with $\epsilon=I^{-1}\sum_{i=1}^Iw_i \epsilon_i$ | $f_a=\log\left(\frac{1-\epsilon}{\epsilon} \right)$,with $\epsilon=I^{-1}\sum_{i=1}^Iw_i \epsilon_i$ | ||||
| Weight of instances via $f_w(i)$ | $f_w=f_a\epsilon_i$ | $f_w=f_a\epsilon_i$ | ||||
| Output function via $f_y$ | $f_y(x) = \text{sign}(x)$ | weighted median of predictions |
Table 6.1: Examples of functions for Adaboost-like algorithms.
Let us comment on the original Adaboost specification. The basic error term $\epsilon_i=\textbf{1}_{\left\{y_i\neq l_m(\textbf{x}_i) \right\}}$ is a dummy number indicating if the prediction is correct (we recall only two values are possible, +1 and -1). The average error $\epsilon\in [0,1]$ is simply a weighted average of individual errors and the weight of the $m^{th}$ learner defined in Equation \@ref(eq:adaboostam) is given by $a_m=\log\left(\frac{1-\epsilon}{\epsilon} \right)$. The function $x\mapsto \log((1-x)x^{-1})$ decreases on $[0,1]$ and switches sign (from positive to negative) at $x=1/2$. Hence, when the average error is small, the learner has a large positive weight but when the error becomes large, the learner can even obtain a negative weight. Indeed, the threshold $\epsilon>1/2$ indicated that the learner is wrong more than 50% of the time. Obviously, this indicates a problem and the learner should even be discarded.
The change in instance weights follows a similar logic. The new weight is proportional to $w_i\left(\frac{1-\epsilon}{\epsilon} \right)^{\epsilon_i}$. If the prediction is right and $\epsilon_i=0$, the weight is unchanged. If the prediction is wrong and $\epsilon_i=1$, the weight is adjusted depending on the aggregate error $\epsilon$. If the error is small and the learner efficient ($\epsilon<1/2$), then $(1-\epsilon)/\epsilon>1$ and the weight of the instance increases. This means that for the next round, the learner will have to focus more on instance $i$.
Lastly, the final prediction of the model corresponds to the sign of the weighted sums of individual predictions: if the sum is positive, the model will predict +1 and it will yield -1 otherwise. The odds of a zero sum are negligible. In the case of numerical labels, the process is slightly more complicated and we refer to Section 3, step 8 of @drucker1997improving for more details on how to proceed.
We end this presentation with one word on instance weighting. There are two ways to deal with this topic. The first one works at the level of the loss functions. For regression trees, Equation \@ref(eq:node) would naturally generalize to $$V^{(k)}_N(c^{(k}), \textbf{w})= \sum_{x_i^{(k)}<c^{(k)}}w_i\left(y_i-m_N^{k,-}(c^{(k)}) \right)^2 + \sum_{x_i^{(k)}>c^{(k)}}w_i\left(y_i-m_N^{k,+}(c^{(k)}) \right)^2,$$
and hence an instance with a large weight $wi$ would contribute more to the dispersion of its cluster. For classification objectives, the alteration is more complex and we refer to Ting (2002) for one example of an instance-weighted tree-growing algorithm. The idea is closely linked to the alteration of the misclassification risk via a loss matrix (see Section 9.2.4 in Hastie, Tibshirani, and Friedman (2009)).
The second way to enforce instance weighting is via random sampling. If instances have weights $w_i$, then the training of learners can be performed over a sample that is randomly extracted with distribution equal to $w_i$. In this case, an instance with a larger weight will have more chances to be represented in the training sample. The original adaboost algorithm relies on this method.
Below, we test an implementation of the original adaboost classifier. As such, we work with the R1M_Usd_C variable and change the model formula. The computational cost of adaboost is high on large datasets, thus we work with a smaller sample and we only impose three iterations.
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
fit_adaboost_C = AdaBoostClassifier(DecisionTreeClassifier(
max_depth=3), # depth of the tree
n_estimators=3) # Number of trees
fit_adaboost_C.fit(X_train, y_c_train) # Fitting the model
AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=3),
n_estimators=3)
Finally, we evaluate the performance of the classifier.
from sklearn.metrics import accuracy_score # introducing buit-in function for accuracy
hitratio=accuracy_score(y_c_test, fit_adaboost_C.predict(X_test)) # Hitratio
print(f'Hit Ratio: {hitratio}')
Hit Ratio: 0.49641066545123064
The accuracy (as evaluated by the hit ratio) is clearly not satisfactory. One reason for this may be the restrictions we enforced for the training (smaller sample and only three trees).
The ideas behind tree boosting were popularized, among others, by Mason et al. (2000), Friedman (2001), and Friedman (2002). In this case, the combination of learners (prediction tools) is not agnostic as in random forest, but adapted (or optimized) at the learner level. At each step $s$, the sum of models $M_S=\sum_{s=1}^{S-1}m_s+m_S$ is such that the last learner $m_S$ was precisely designed to reduce the loss of $M_S$ on the training sample.
Below, we follow closely the original work of T. Chen and Guestrin (2016) because their algorithm yields incredibly accurate predictions and also because it is highly customizable. It is their implementation that we use in our empirical section. The other popular alternative is lightgbm (see Ke et al. (2017)). What XGBoost seeks to minimise is the objective
$O=\underbrace{\sum_{i=1}^I \text{loss}(y_i,\tilde{y}_i)}_{\text{error term}} \quad + \underbrace{\sum_{j=1}^J\Omega(T_j)}_{\text{regularisation term}}.$
The first term (over all instances) measures the distance between the true label and the output from the model. The second term (over all trees) penalises models that are too complex.
For simplicity, we propose the full derivation with the simplest loss function $\text{loss}(y,\tilde{y})=(y-\tilde{y})^2$, so that: $O=\sum_{i=1}^I \left(y_i-m_{J-1}(\mathbf{x}_i)-T_J(\mathbf{x}_i)\right)^2+ \sum_{j=1}^J\Omega(T_j).$
Let us assume that we have already built all trees $T_{j}$ up to $j=1,\dots,J-1$ (and hence model $M_{J-1}$): how to choose tree $T_J$ optimally? We rewrite \begin{align*} O&=\sum_{i=1}^I \left(y_i-m_{J-1}(\mathbf{x}_i)-T_J(\mathbf{x}_i)\right)^2+ \sum_{j=1}^J\Omega(T_j) \\ &=\sum_{i=1}^I\left\{y_i^2+m_{J-1}(\mathbf{x}_i)^2+T_J(\mathbf{x}_i)^2 \right\} + \sum_{j=1}^{J-1}\Omega(T_j)+\Omega(T_J) \quad \text{(squared terms + penalisation)}\\ & \quad -2 \sum_{i=1}^I\left\{y_im_{J-1}(\mathbf{x}_i)+y_iT_J(\mathbf{x}_i)-m_{J-1}(\mathbf{x}_i) T_J(\mathbf{x}_i))\right\}\quad \text{(cross terms)} \\ &= \sum_{i=1}^I\left\{-2 y_iT_J(\mathbf{x}_i)+2m_{J-1}(\mathbf{x}_i) T_J(\mathbf{x}_i))+T_J(\mathbf{x}_i)^2 \right\} +\Omega(T_J) + c \end{align*} All terms known at step $J$ (i.e., indexed by $J-1$) vanish because they do not enter the optimisation scheme. The are embedded in the constant $c$.
Things are fairly simple with quadratic loss. For more complicated loss functions, Taylor expansions are used (see the original paper).
In order to go any further, we need to specify the way the penalisation works. For a given tree $T$, we specify its structure by $T(x)=w_{q(x)}$, where $w$ is the output value of some leaf and $q(\cdot)$ is the function that maps an input to its final leaf. This encoding is illustrated in Figure 6.5. The function $q$ indicates the path, while the vector $\textbf{w}=w_i$ codes the terminal leaf values.
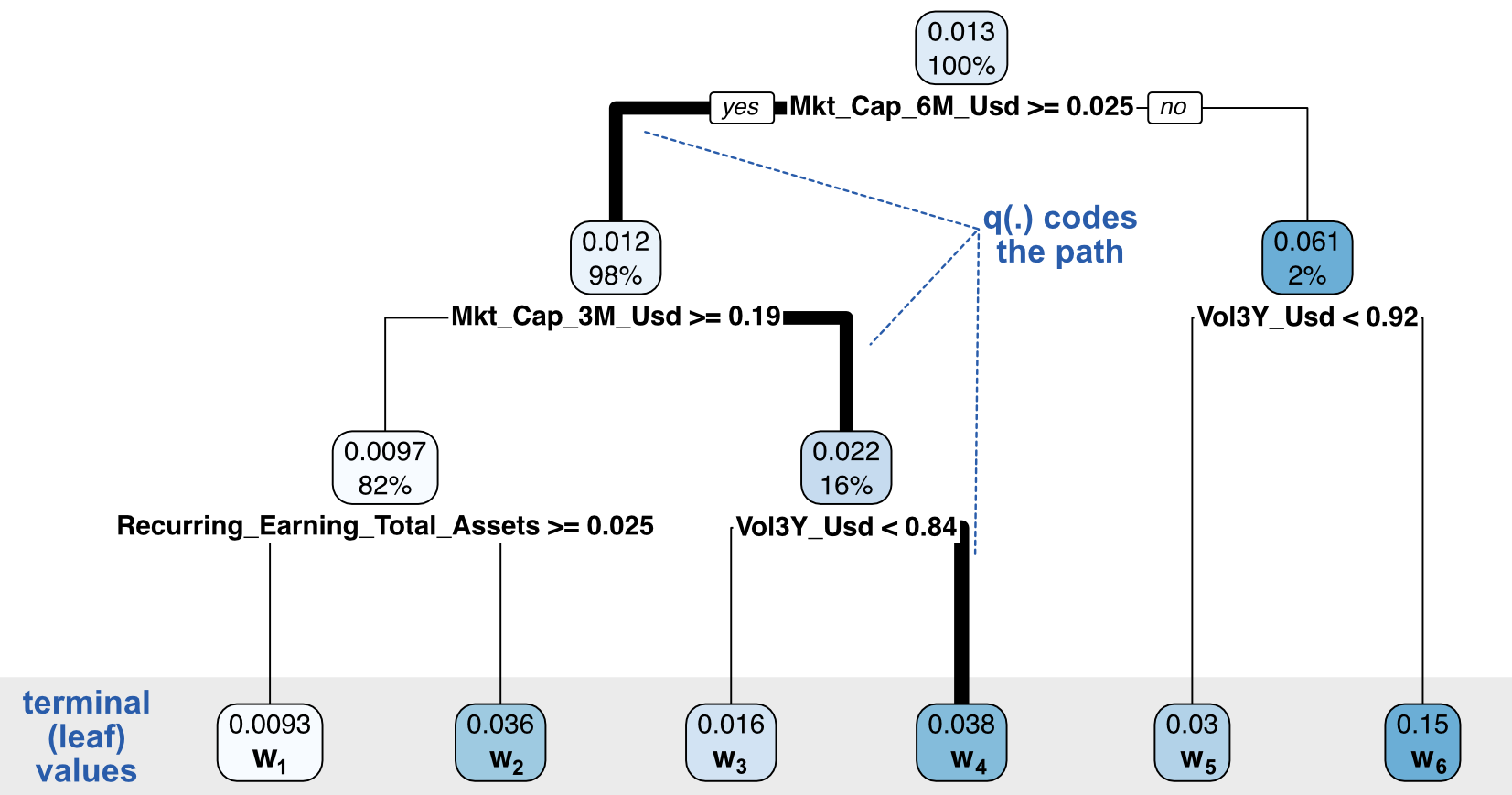 FIGURE 6.5: Coding a decision tree: decomposition between strucutre and node and leaf values.
FIGURE 6.5: Coding a decision tree: decomposition between strucutre and node and leaf values.
We write $l=1,\dots,L$ for the indices of the leafs of the tree. In XGBoost, complexity is defined as: $\Omega(T)=\gamma L+\frac{\lambda}{2}\sum_{l=1}^Lw_l^2,$ where
The first penalization term reduces the depth of the tree while the second shrinks the size of the adjustments that will come from the latest tree.
We aggregate both sections of the objective (loss and penalization). We write $I_l$ for the set of the indices of the instances belonging to leaf $l$. Then,
\begin{align*}
O&= 2\sum_{i=1}^I\left\{ -y_iT_J(\mathbf{x}_i)+m_{J-1}(\mathbf{x}_i) T_J(\mathbf{x}_i))+\frac{T_J(\mathbf{x}_i)^2}{2} \right\} + \gamma L+\frac{\lambda}{2}\sum_{l=1}^Lw_l^2 \\
&=2\sum_{i=1}^I\left\{- y_iw_{q(\mathbf{x}_i)}+m_{J-1}(\mathbf{x}_i)w_{q(\mathbf{x}_i)})+\frac{w_{q(\mathbf{x}_i)}^2}{2} \right\} + \gamma L+\frac{\lambda}{2}\sum_{l=1}^Lw_l^2 \\
&=2 \sum_{l=1}^L \left(w_l\sum_{i\in I_l}(-y_i +m_{J-1}(\mathbf{x}_i))+ \frac{w_l^2}{2}\sum_{i\in I_l}\left(1+\frac{\lambda}{2}\right)\right)+ \gamma L
\end{align*}
The function is of the form $aw_l+\frac{b}{2}w_l^2$, which has minimum values $-\frac{a^2}{2b}$ at point $w_l=-a/b$. Thus, writing #(.) for the cardinal function that counts the number of items in a set,
\begin{align}
(\#eq:xgbweight)
\mathbf{\rightarrow} \quad w^*_l&=\frac{\sum_{i\in I_l}(y_i -m_{J-1}(\mathbf{x}_i))}{\left(1+\frac{\lambda}{2}\right)\#\{i\in I_l\}}, \text{ so that} \\
O_L(q)&=-\frac{1}{2}\sum_{l=1}^L \frac{\left(\sum_{i\in I_l}(y_i -m_{J-1}(\mathbf{x}_i))\right)^2}{\left(1+\frac{\lambda}{2}\right)\#\{i\in I_l\}}+\gamma L, \nonumber
\end{align}
where we added the dependence of the objective both in $q$ (structure of tree) and $L$ (number of leaves). Indeed, the meta-shape of the tree remains to be determined.
Final problem: the tree structure! Let us take a step back. In the construction of a simple regression tree, the output value at each node is equal to the average value of the label within the node (or cluster). When adding a new tree in order to reduce the loss, the node values must be computed completely differently, which is the purpose of Equation (6.5).
Nonetheless, the growing of the iterative trees follows similar lines as simple trees. Features must be tested in order to pick the one that minimizes the objective for each given split. The final question is then: what's the best depth and when to stop growing the tree? The method is to
$\text{Gain}_O$ is the original gain (no split) and $\text{Gain}_L$ and $\text{Gain}_R$ are the gains of the left and right cluster, respectively. One work about the $-\gamma$ adjustment in the above formula: there is one unit of new leaves (two new minus one old)! This makes a one leaf difference, hence $\Delta L =1$ and the penalization intensity for each new leaf is equal to $\gamma$.
Lastly, we underline the fact that XGBoost also applies a learning rate: each new tree is scaled by a factor $\eta$, with $\eta \in (0,1]$. After each step of boosting the new tree $T_J$ sees its values discounted by multiplied them by $\eta$. This is very useful because a pure aggregation of 100 optimized trees is the best way to overfit the training sample.
Several additional features are available to further prevent boosted trees to overfit. Indeed, given a sufficiently large number of trees, the aggregation is able to match the training sample very well, but may fail to generalize well out-of-sample.
Following the pioneering work of Srivastava et al. (2014), the DART (Dropout for Additive Regression Trees) model was proposed by Rashmi and Gilad-Bachrach (2015). The idea is to omit a specified number of trees during training. The trees that are removed from the model are chosen randomly. The full specifications can be found at https://xgboost.readthedocs.io/en/latest/tutorials/dart.html.
Monotonicity constraints are another element that is featured both in xgboost and lightgbm. Sometimes, it is expected that one particular feature has a monotonic impact on the label. For instance, if one deeply believes in momentum, then past returns should have an increasing impact on future returns (in the cross-section of stocks).
Given the recursive nature of the splitting algorithm, it is possible to choose when to perform a split (according to a particular variable) and when not to. In Figure 6.6 , we show how the algorithm proceeds. All splits are performed according to the same feature. For the first split, things are easy because it suffices to verify that the averages of each cluster are ranked in the right direction. Things are more complicated for the splits that occur below. Indeed, the average values set by all above splits matter as they give bounds for acceptable values for the future average values in lower splits. If a split violates these bounds, then it is overlooked and another variable will be chosen instead.
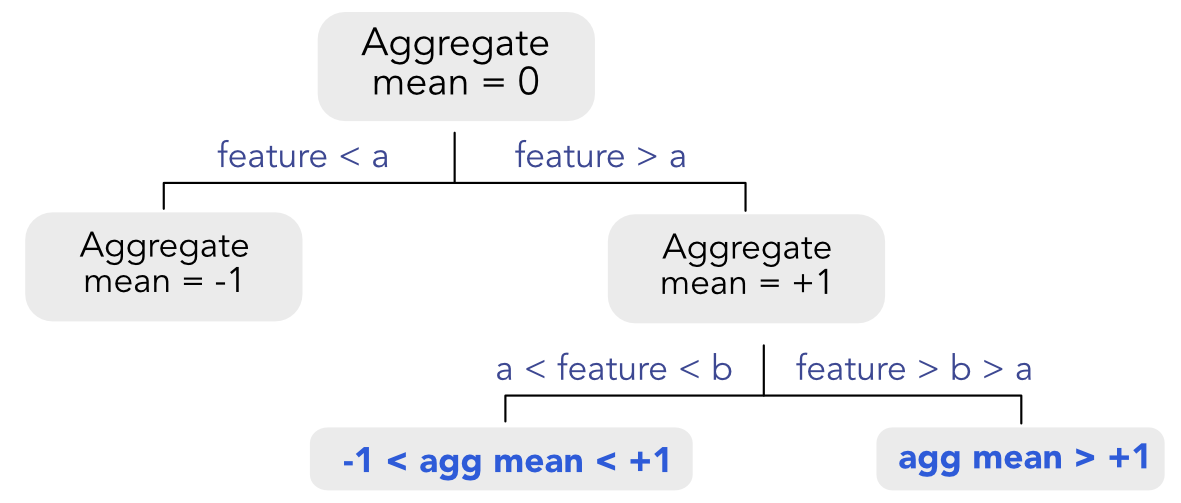 FIGURE 6.6: Imposing monotonic constraints. The constraints are shown in bold blue in the bottom leaves.
FIGURE 6.6: Imposing monotonic constraints. The constraints are shown in bold blue in the bottom leaves.
In this section, we train a model using the XGBoost library. Other options include catboost, gbm, lightgbm, and h2o’s own version of boosted machines. Unlike many other packages, the XGBoost function requires a particular syntax and dedicated formats. The first step is thus to encapsulate the data accordingly.
Moreover, because training times can be long, we shorten the training sample as advocated in Coqueret and Guida (2020). We retain only the 40% most extreme observations (in terms of label values: top 20% and bottom 20%) and work with the small subset of features. In all coding sections dedicated to boosted trees in this book, the models will be trained with only 7 features.
import xgboost as xgb # The package for boosted trees
data_ml['R1M_Usd_quantile'] = data_ml.groupby('date')['R1M_Usd'].transform( # creating quantile...
lambda x: pd.qcut(x, 100, labels=False, duplicates=('drop'), precision=50)) # ...for selecting extreme values
boolean_quantile=(data_ml.loc[separation_mask]['R1M_Usd_quantile']. # boolean array for selecting rows
values<=0.2) | (data_ml.loc[separation_mask]['R1M_Usd_quantile'].values>=0.8) # selecting extreme values
###############################################################################
train_features_xgb=training_sample.loc[boolean_quantile,features_short] # Independent variables
train_label_xgb=training_sample.loc[boolean_quantile,'R1M_Usd'] # Dependent variable
train_matrix_xgb=xgb.DMatrix(train_features_xgb, label=train_label_xgb) # XGB format!
The second (optional) step is to determine the monotonicity constraints that we want to impose. For simplicity, we will only enforce three constraints on
mono_const="(0, 0, -1, 1, 0, -1, 0)" # Initialize the vector -- "-1" == decreasing, "+1" increasing
# Decreasing in market cap -- mono_const[2]
# Increasing in past return -- mono_const[3]
# Decreasing in price-to-book -- mono_const[5]
The third step is to train the model on the formatted training data. We include the monotonicity constraints and the DART feature (via rate_drop). Just like random forests, boosted trees can grow individual trees on subsets of the data: both row-wise (by selecting random instances) and column-wise (by keeping a smaller portion of predictors). These options are implemented below with the subsample and colsample_bytree in the arguments of the function.
params={'eta' : 0.3, # Learning rate
'objective' : "reg:squarederror", # Objective function
'max_depth' : 4, # Maximum depth of trees
'subsample' : 0.6, # Train on random 60% of sample
'colsample_bytree' : 0.7, # Train on random 70% of predictors
'lambda' : 1, # Penalisation of leaf values
'gamma' : 0.1, # Penalisation of number of leaves
'nrounds' : 30, # Number of trees used (rather low here)
'monotone_constraints' : mono_const, # Monotonicity constraints
'rate_drop' : 0.1, # Drop rate for DART
'verbose' : 0} # No comment from the algo
fit_xgb =xgb.train(params, train_matrix_xgb)
[10:27:17] WARNING: C:/Users/Administrator/workspace/xgboost-win64_release_1.6.0/src/learner.cc:627:
Parameters: { "nrounds", "rate_drop", "verbose" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
Finally, we evaluate the performance of the model. Note that before that, a proper formatting of the testing sample is required.
test_features_xgb=testing_sample[features_short] # Test sample => XGB format
test_matrix_xgb=xgb.DMatrix(test_features_xgb, label=y_test) # XGB format!
fit_xgb.predict(test_matrix_xgb)
mse = np.mean((fit_xgb.predict(test_matrix_xgb) - y_test)**2)
print(f'MSE: {mse}')
MSE: 0.03781719994386558
hitratio = np.mean(fit_xgb.predict(test_matrix_xgb) * y_test > 0)
print(f'Hit Ratio: {hitratio}')
Hit Ratio: 0.5460346399270738
The performance is comparable to those observed for other predictive tools. As a final exercise, we show one implementation of a classification task under XGBoost. Only the label changes. In XGBoost, labels must be coded with integer number, starting at zero exactly.
train_label_xgb_C=training_sample.loc[boolean_quantile,'R1M_Usd_C'] # Dependent variable
train_matrix_xgb_C=xgb.DMatrix(train_features_xgb, label=train_label_xgb_C) # XGB format!
When working with categories, the loss function is usually the softmax function (see Section 2.1).
params_C={'eta' : 0.8, # Learning rate
'objective' : "multi:softmax", # Objective function
'max_depth' : 4, # Maximum depth of trees
'num_class' : 2, # number of classes
'nrounds' : 10, # Number of trees used (rather low here)
'verbose' : 0} # No comment from the algo
fit_xgb_C =xgb.train(params_C, train_matrix_xgb_C)
[10:29:12] WARNING: C:/Users/Administrator/workspace/xgboost-win64_release_1.6.0/src/learner.cc:627:
Parameters: { "nrounds", "verbose" } might not be used.
This could be a false alarm, with some parameters getting used by language bindings but
then being mistakenly passed down to XGBoost core, or some parameter actually being used
but getting flagged wrongly here. Please open an issue if you find any such cases.
We can then proceed to the assessment of the quality of the model. We adjust the prediction to the value of the true label and count the proportion of accurate forecasts.
hitratio = np.mean(fit_xgb_C.predict(test_matrix_xgb) == y_c_test)
print(f'Hit Ratio: {hitratio}')
Hit Ratio: 0.49846171376481313
Consistently with the previous classification attempts, the results are underwhelming, as if switching to binary labels incurred a loss of information.
In the computation of the aggregate loss, it is possible to introduce some flexibility and assign weights to instances: $$O=\underbrace{\sum_{i=1}^I\mathcal{W}_i \times \text{loss}(y_i,\tilde{y}_i)}_{\text{weighted error term}} \quad + \underbrace{\sum_{j=1}^J\Omega(T_j)}_{\text{regularisation term (unchanged)}}.$$
In factor investing these weights can very well depend on the feature values ($\mathcal{W}_i=\mathcal{W}_i(\textbf{x}_i)$). For instance, for one particular characteristic $\textbf{x}^k$, weights can be increasing thereby giving more importance to assets with high values of this characteristic (e.g., value stocks are favored compared to growth stocks). One other option is to increase weights when the values of the characteristic become more extreme (deep value and deep growth stocks have larger weights). If the features are uniform, the weights can simply be $\mathcal{W}_i(x_i^k)\propto|x_i^k-0.5|$: firms with median value 0.5 have zero weight and as the feature value shifts towards 0 or 1, the weight increases. Specifying weights on instances biases the learning process just like views introduced à la @black1992global influence the asset allocation process. The difference is that the nudge is performed well ahead of the portfolio choice problem.
In xgboost, the implementation instance weighting is done very early, in the definition of the xgb.DMatrix:
inst_weights = np.random.uniform(0,1,(train_features_xgb.shape[0],1)) # Random weights
train_matrix_xgb=xgb.DMatrix(train_features_xgb, label=train_label_xgb, # XGB format!
weight = inst_weights) # Weights!
Then, in the subsequent stages, the optimization will be performed with these hard-coded weights. The splitting points can be altered (via the total weighted loss in clusters) and the terminal weight values (6.5) are also impacted.
We end this chapter by a discussion on the choice of predictive engine with a view towards portfolio construction. As recalled in Chapter 3, the ML signal is just one building stage of construction of the investment strategy. At some point, this signal must be translated into portfolio weights.
From this perspective, simple trees appear suboptimal. Tree depth are usually set between 3 and 6. This implies between 8 and 64 terminal leaves at most, with possibly very unbalanced clusters. The likelihood of having one cluster with 20% to 30% of the sample is high. This means that when it comes to predictions, roughly 20% to 30% of the instances will be given the same value.
On the other side of the process, portfolio policies commonly have a fixed number of assets. Thus, having assets with equal signal does not permit to discriminate and select a subset to be included in the portfolio. For instance, if the policy requires exactly 100 stocks and 105 stocks have the same signal, the signal cannot be used for selection purposes. It would have to be combined with exogenous information such as the covariance matrix in a mean-variance type allocation.
Overall, this is one reason to prefer aggregate models. When the number of learners is sufficiently large (5 is almost enough), the predictions for assets will be unique and tailored to these assets. It then becomes possible to discriminate via the signal and select only those assets that have the most favorable signal. In practice, random forests and boosted trees are probably the best choices.
Using the formula in the chunks above, build two simple trees on the training sample with only one parameter: cp. For the first tree, take cp=0.001 and for the second take cp=0.01. Evaluate the performance of both models on the testing sample. Comment.
With the smaller set of predictors, build random forests on the training sample. Restrict the learning on 30,000 instances and over 5 predictors. Construct the forests on 10, 20, 40, 80 and 160 trees and evaluate their performance on the training sample. Is complexity worthwhile in this case and why?
Plot a tree based on data from calendar year 2008 and then from 2009. Compare.
Ballings, Michel, Dirk Van den Poel, Nathalie Hespeels, and Ruben Gryp. 2015. “Evaluating Multiple Classifiers for Stock Price Direction Prediction.” Expert Systems with Applications 42 (20): 7046–56.
Biau, Gérard. 2012. “Analysis of a Random Forests Model.” Journal of Machine Learning Research 13 (Apr): 1063–95.
Biau, Gérard, Luc Devroye, and GAbor Lugosi. 2008. “Consistency of Random Forests and Other Averaging Classifiers.” Journal of Machine Learning Research 9 (Sep): 2015–33.
Black, Fischer, and Robert Litterman. 1992. “Global Portfolio Optimization.” Financial Analysts Journal 48 (5): 28–43.
Breiman, Leo. 2001. “Random Forests.” Machine Learning 45 (1): 5–32.
Breiman, Leo, Jerome Friedman, Charles J. Stone, and R. A. Olshen. 1984. Classification and Regression Trees. Chapman & Hall.
Breiman, Leo, and others. 2004. “Population Theory for Boosting Ensembles.” Annals of Statistics 32 (1): 1–11.
Bryzgalova, Svetlana, Markus Pelger, and Jason Zhu. 2019. “Forest Through the Trees: Building Cross-Sections of Stock Returns.” SSRN Working Paper 3493458.
Chen, Tianqi, and Carlos Guestrin. 2016. “Xgboost: A Scalable Tree Boosting System.” In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785–94. ACM.
Coqueret, Guillaume, and Tony Guida. 2020. “Training Trees on Tails with Applications to Portfolio Choice.” Annals of Operations Research 288: 181–221.
Denil, Misha, David Matheson, and Nando De Freitas. 2014. “Narrowing the Gap: Random Forests in Theory and in Practice.” In International Conference on Machine Learning, 665–73.
Drucker, Harris. 1997. “Improving Regressors Using Boosting Techniques.” In International Conference on Machine Learning, 97:107–15.
Freund, Yoav, and Robert E Schapire. 1996. “Experiments with a New Boosting Algorithm.” In Machine Learning: Proceedings of the Thirteenth International Conference, 96:148–56.
Freund, Yoav, and Robert E Schapire. 1997. “A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting.” Journal of Computer and System Sciences 55 (1): 119–39.
Friedman, Jerome H. 2001. “Greedy Function Approximation: A Gradient Boosting Machine.” Annals of Statistics, 1189–1232.
Friedman, Jerome H. 2002. “Stochastic Gradient Boosting.” Computational Statistics & Data Analysis 38 (4): 367–78.
Friedman, Jerome, Trevor Hastie, Robert Tibshirani, and others. 2000. “Additive Logistic Regression: A Statistical View of Boosting (with Discussion and a Rejoinder by the Authors).” Annals of Statistics 28 (2): 337–407.
Gu, Shihao, Bryan T Kelly, and Dacheng Xiu. 2020b. “Empirical Asset Pricing via Machine Learning.” Review of Financial Studies 33 (5): 2223–73.
Guida, Tony, and Guillaume Coqueret. 2018a. “Ensemble Learning Applied to Quant Equity: Gradient Boosting in a Multifactor Framework.” In Big Data and Machine Learning in Quantitative Investment, 129–48. Wiley.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning. Springer.
Ho, Tin Kam. 1995. “Random Decision Forests.” In Proceedings of 3rd International Conference on Document Analysis and Recognition, 1:278–82. IEEE.
Huck, Nicolas. 2019. “Large Data Sets and Machine Learning: Applications to Statistical Arbitrage.” European Journal of Operational Research 278 (1): 330–42.
Ke, Guolin, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. “Lightgbm: A Highly Efficient Gradient Boosting Decision Tree.” In Advances in Neural Information Processing Systems, 3146–54.
Krauss, Christopher, Xuan Anh Do, and Nicolas Huck. 2017. “Deep Neural Networks, Gradient-Boosted Trees, Random Forests: Statistical Arbitrage on the S&P 500.” European Journal of Operational Research 259 (2): 689–702.
Mason, Llew, Jonathan Baxter, Peter L Bartlett, and Marcus R Frean. 2000. “Boosting Algorithms as Gradient Descent.” In Advances in Neural Information Processing Systems, 512–18.
Moritz, Benjamin, and Tom Zimmermann. 2016. “Tree-Based Conditional Portfolio Sorts: The Relation Between Past and Future Stock Returns.” SSRN Working Paper 2740751.
Olson, Randal S, William La Cava, Zairah Mustahsan, Akshay Varik, and Jason H Moore. 2018. “Data-Driven Advice for Applying Machine Learning to Bioinformatics Problems.” arXiv Preprint, no. 1708.05070.
Patel, Jigar, Sahil Shah, Priyank Thakkar, and K Kotecha. 2015a. “Predicting Stock and Stock Price Index Movement Using Trend Deterministic Data Preparation and Machine Learning Techniques.” Expert Systems with Applications 42 (1): 259–68.
Patel, Jigar, Sahil Shah, Priyank Thakkar, and Ketan Kotecha. 2015b. “Predicting Stock Market Index Using Fusion of Machine Learning Techniques.” Expert Systems with Applications 42 (4): 2162–72.
Rashmi, Korlakai Vinayak, and Ran Gilad-Bachrach. 2015. “DART: Dropouts Meet Multiple Additive Regression Trees.” In AISTATS, 489–97.
Ridgeway, Greg, David Madigan, and Thomas Richardson. 1999. “Boosting Methodology for Regression Problems.” In AISTATS.
Schapire, Robert E. 1990. “The Strength of Weak Learnability.” Machine Learning 5 (2): 197–227.
Schapire, Robert E. 2003. “The Boosting Approach to Machine Learning: An Overview.” In Nonlinear Estimation and Classification, 149–71. Springer.
Schapire, Robert E, and Yoav Freund. 2012. Boosting: Foundations and Algorithms. MIT Press.
Scornet, Erwan, Gérard Biau, Jean-Philippe Vert, and others. 2015. “Consistency of Random Forests.” Annals of Statistics 43 (4): 1716–41.
Simonian, Joseph, Chenwei Wu, Daniel Itano, and Vyshaal Narayanam. 2019. “A Machine Learning Approach to Risk Factors: A Case Study Using the Fama-French-Carhart Model.” Journal of Financial Data Science 1 (1): 32–44.
Srivastava, Nitish, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. “Dropout: A Simple Way to Prevent Neural Networks from Overfitting.” Journal of Machine Learning Research 15 (1): 1929–58.
Ting, Kai Ming. 2002. “An Instance-Weighting Method to Induce Cost-Sensitive Trees.” IEEE Transactions on Knowledge & Data Engineering, no. 3: 659–65.
Yin, Anwen. 2020. “Equity Premium Prediction and Optimal Portfolio Decision with Bagging.” North American Journal of Economics and Finance, 101274.
footnotes
See www.kaggle.com. ↩︎
The strength is measured as the average margin, i.e. the average of $m_g$ when there is only one tree.↩︎
See, e.g., http://docs.h2o.ai/h2o/latest-stable/h2o-r/docs/reference/h2o.randomForest.html↩︎
The Real Adaboost of Friedman et al. (2000) has a different output: the probability of belonging to a particular class.↩︎